Overview
Ziren is an open-source, simple, stable, and universal zero-knowledge virtual machine on MIPS32r2 instruction set architecture(ISA).
Ziren is the industry's first zero-knowledge proof virtual machine supporting the MIPS instruction set, developed by the ZKM team, enabling zero-knowledge proof generation for general-purpose computation. Ziren is fully open-source and comes equipped with a comprehensive developer toolkit and an efficient proof network. The Entangled Rollup protocol, designed specifically to utilize Ziren, is a native asset cross-chain circulation protocol, with typical application cases including the Metis Hybrid Rollup design and the GOAT Network Bitcoin L2.
Architectural Workflow
The workflow of Ziren is as follows:
-
Frontend Compilation
Source code (Rust) → MIPS assembly → Optimized MIPS instructions for algebraic representation.
-
Arithmetization
Emulates MIPS instructions while generating execution traces with embedded constraints (ALU, memory consistency, range checks, etc.) and treating columns of execution traces as polynomials.
-
STARK Proof Generation
Compiles traces into Plonky3 AIR (Algebraic Intermediate Representation), and proves the constraints using the Fast Reed-Solomon Interactive Oracle Proof of Proximity (FRI) technique.
-
STARK Compression and STARK-to-SNARK Proof Recursion
To produce a constant-size proof, Ziren supports first generating a recursive argument to compress STARK proofs, and then wrapping the compressed proof into a SNARK for efficient on-chain verification.
-
Verification
The SNARK proof can be verified on-chain. The STARK proof can be verified on any verification layer for faster optimistic finalization.
Core Innovations
Ziren is the world's first MIPS-based zkVM, achieving the industry-leading performance through the following core innovations:
-
Ziren Compiler
Implement the first zero-knowledge compiler for MIPS32r2. Convert standard MIPS binaries into constraint systems with deterministic execution traces using proof-system-friendly compilation and PAIR builder.
-
"Area Minimization" Chip Design
Ziren partitions circuit constraints into highly segmented chips, strategically minimizing the total layout area while preserving logical completeness. This fine-grained decomposition enables compact polynomial representations with reduced commitment and evaluation overhead, thereby directly optimizing ZKP proof generation efficiency.
-
Multiset Hashing for Memory Consistency Checking
Replaces MerkleTree hashing with Multiset Hashing for memory consistency checks, significantly reducing witness data and enabling parallel verification.
-
KoalaBear Prime Field
Using KoalaBear Prime \(2^{31} - 2^{24} + 1\) instead of 64-bit Goldilocks Prime, accelerating algebraic operations in proofs.
-
Hardware Acceleration
Ziren supports AVX2/512 and GPU acceleration. The GPU prover can achieve 30x faster for Core proof, 15x for Aggregation proof and 30x for BN254 Wrapping proof than CPU prover.
-
Integrating Cutting-edge Industry Advancements
Ziren constructs its zero-knowledge proof system by integrating Plonky3's optimized Fast Reed-Solomon IOP (FRI) protocol and adapting SP1's circuit builder, recursion compiler, and precompiles for the MIPS architecture.
Target Use Cases
Ziren enables universal verifiable computation via STARK proofs, including:
-
Bitcoin L2
GOAT Network is a Bitcoin L2 built on Ziren and BitVM2 to improve the scalability and interoperability of Bitcoin.
-
ZK-OP (HybridRollups)
Combines optimistic rollup’s cost efficiency with validity proof verifiability, allowing users to choose withdrawal modes (fast/high-cost vs. slow/low-cost) while enhancing cross-chain capital efficiency.
-
Entangled Rollup
Entanglement of rollups for trustless cross-chain communication, with universal L2 extension resolving fragmented liquidity via proof-of-burn mechanisms (e.g. cross-chain asset transfers).
-
zkML Verification Protects sensitive ML model/data privacy (e.g. healthcare), allowing result verification without exposing raw inputs (e.g. doctors validating diagnoses without patient ECG data).
Installation
Ziren is now available for Linux and macOS systems.
Requirements
Get Started
Option 1: Quick Install
To install the Ziren toolchain, use the zkmup installer. Simply open your terminal, run the command below, and follow the on-screen instructions:
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/ProjectZKM/toolchain/refs/heads/main/setup.sh | sh
It will:
- Download the
zkmupinstaller. - Automatically utilize
zkmupto install the latest Ziren Rust toolchain which has support for themipsel-zkm-zkvm-elfcompilation target.
List all available toolchain versions:
$ zkmup list-available
20250224 20250108 20241217
Now you can run Ziren examples or unit tests.
git clone https://github.com/ProjectZKM/Ziren
cd Ziren && cargo test -r
Troubleshooting
The following error may occur:
cargo build --release
cargo: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.32' not found (required by cargo)
cargo: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.33' not found (required by cargo)
cargo: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.34' not found (required by cargo)
Currently, our prebuilt binaries are built for Ubuntu 22.04 and macOS. Systems running older GLIBC versions may experience compatibility issues and will need to build the toolchain from source.
Option 2: Building from Source
For more details, please refer to document toolchain.
Quickstart
Get started with Ziren by executing, generating and verifying a proof for your custom program.
Overview of all the steps to create your Ziren proof:
- Create a new project using the Ziren project template or CLI
- Compile and execute your guest program
- Generate a ZK proof of your program locally or via the proving network
- Verify the proof of your program, including on-chain verification
Creating a new project
After installing the Ziren toolchain, you can create a new project either directly via the CLI or by cloning the project template.
Using the CLI
Install the CLI locally from source:
#![allow(unused)] fn main() { cd Ziren/crates/cli cargo install --locked --force --path . }
You can now create a bare new project using the new command:
#![allow(unused)] fn main() { cargo ziren new --bare <NEW_PROJECT> }
To view additional CLI commands, including build for compiling a program and vkey for displaying the guest’s verification key hash:
#![allow(unused)] fn main() { cargo ziren --help }
Using the Project Template:
You can also create a new project by cloning the Ziren Project Template, which includes:
- Guest and host Rust programs for proving a Fibonacci sequence
- Solidity contracts for on-chain verification
- Sample inputs/outputs and test data
The project directory has the following structure:
.
├── contracts
│ ├── lib
│ ├── script
│ │ ├── ZKMVerifierGroth16.s.sol
│ │ └── ZKMVerifierPlonk.s.sol
│ ├── src
│ │ ├── Fibonacci.sol
│ │ ├── IZKMVerifier.sol
│ │ ├── fixtures
│ │ │ ├── groth16-fixture.json
│ │ │ └── plonk-fixture.json
│ │ └── v1.0.0
│ │ ├── Groth16Verifier.sol
│ │ ├── PlonkVerifier.sol
│ │ ├── ZKMVerifierGroth16.sol
│ │ └── ZKMVerifierPlonk.sol
│ └── test
│ ├── Fibonacci.t.sol
│ ├── ZKMVerifierGroth16.t.sol
│ └── ZKMVerifierPlonk.t.sol
├── guest
│ ├── Cargo.toml
│ └── src
│ └── main.rs
├── host
│ ├── Cargo.toml
│ ├── bin
│ │ ├── evm.rs
│ │ └── vkey.rs
│ ├── build.rs
│ ├── src
│ │ └── main.rs
│ └── tool
│ ├── ca.key
│ ├── ca.pem
│ └── certgen.sh
There are three main directories in the project:
guest: contains the guest program executed inside the zkVM.
./guest/src/main.rs: guest program that contains your core program logic to be executed inside the zkVM.
host: contains the host program that controls the end-to-end process of compiling and executing the guest, generating a proof and outputting verifier artifacts.
./host/src/main.rs: host program that contains the host logic for your program../host/bin/evm.rsand./host/bin/vkey.rs: used to generate EVM-compatible verifier artifacts and print the verifying key../host/tool/: contains the certificates and scripts for network proving../host/build.rs: contains custom build logic including compiling the guest to an ELF artifact whenever the host is built.
contracts: contains the Solidity verifier smart contracts and test scripts for on-chain verification.
contracts/src/Fibonacci.sol: a sample Solidity contract demonstrating input/output structure for the Fibonacci program.IZKMVerifier.sol: implemented Ziren interface for verifiers.fixtures/: contains the public outputs, proof and verification keys in JSON format.v1.0.0/: contains the Groth16 and PLONK verifier implementations and wrapper contracts.contracts/script/: contains forge scripts to deploy the verifier contracts.contracts/test/: contains Foundry tests to validate verifier functionality.
./guest/src/main.rs and ./host/bin/main.rs contain the host and guest implementation of the Fibonacci example. You can change the content of these programs to fit your intended use case.
Building the program
The guest program is compiled into a MIPS executable ELF through ./host/build.rs. The generated ELF file is stored in ./target/elf-compilation
Executing the program
You can execute the program and display the output without generating a proof to check its output:
cd host
cargo run --release -- --execute
Sample output for the Fibonacci program example in the template:
n: 20
Program executed successfully.
n: 20
a: 6765
b: 10946
Values are correct!
Number of cycles: 6755
Generating a proof for the program
The generated ELF binary will be used for proof generation. Generate a proof for your guest program with the following command:
#![allow(unused)] fn main() { cargo run --release -- --<PROOF_TYPE> // for core and compressed proofs cargo run --release --bin evm -- --system <PROOF_TYPE> // for EVM-compatible proofs }
Within the project template, there are three types of proofs that can be generated:
- Core proof — generated by default:
#![allow(unused)] fn main() { cargo run --release -- --core }
- Compressed proof — constant in size, ideal for reducing costs:
#![allow(unused)] fn main() { cargo run --release -- --compressed }
- EVM-compatible proof — includes PLONK and Groth16 proofs.
For Groth16 proofs — recommended for on-chain proof generation:
#![allow(unused)] fn main() { cd host cargo run --release --bin evm -- --system groth16 }
The output includes public values, the verifying keys, and proof bytes. An example output:
n: 20
Proof System: Groth16
Setting environment variables took 7.967µs
Reading R1CS took 13.859710286s
Reading proving key took 1.053438083s
Reading witness file took 162.594µs
Deserializing JSON data took 8.149672ms
Generating witness took 144.081308ms
16:57:23 DBG constraint system solver done nbConstraints=7189516 took=1561.336988
16:57:39 DBG prover done acceleration=none backend=groth16 curve=bn254 nbConstraints=7189516 took=16100.719342
Generating proof took 17.662248261s
ignoring uninitialized slice: Vars []frontend.Variable
ignoring uninitialized slice: Vars []frontend.Variable
ignoring uninitialized slice: Vars []frontend.Variable
16:57:39 DBG verifier done backend=groth16 curve=bn254 took=0.720668
Verification Key: 0x009f93857b6ce5bea9e982a82efa735aa57c0af27165b85ad17f21f9d3aae01a
Public Values: 0x00000000000000000000000000000000000000000000000000000000000000140000000000000000000000000000000000000000000000000000000000001a6d0000000000000000000000000000000000000000000000000000000000002ac2
Proof Bytes: 0x00cd9fa*f08b496bc4ff57a76d69719938a872d4b95f2f638b5f21f2b0cef825606bc14032748e2a86a8dadb00de79f88c650fa2f83813e4f69661b15600d09e9f328b7332dddaeb8dc27519c906bea438929e5474fe76dc940ea6ec3b50ce898a54c339d1c1ece67e746335652d5afb0d950d19960ef34dc7885d99296cad3b1385f9c161ab54408afffb8143708737c89c54988b3512478b79affac241bd08ba4dc75da105764b63b6101fdf06cdbd136a371f932d769c2cd6ba4b699fa61a2bfb5ad5215b4b64f1388484291240faf87c09a04d8ee2a7c47d3f68c6509ab172fecfffd02a2edee4e7deaf93557e22bc99fd3d7f2bf1af15b40b7d09685e6b8d528a122
For PLONK proofs — larger in size compared to Groth16, but with no trusted setup:
#![allow(unused)] fn main() { cargo run --release --bin evm -- --system plonk }
Proof fixtures will be saved in ./contracts/src/fixtures/ to be used for on-chain verification. These contain the public outputs, proof and verification keys in JSON format. An example of groth16-fixture.json :
{
"a": 6765,
"b": 10946,
"n": 20,
"vkey": "0x009f93857b6ce5bea9e982a82efa735aa57c0af27165b85ad17f21f9d3aae01a",
"publicValues": "0x00000000000000000000000000000000000000000000000000000000000000140000000000000000000000000000000000000000000000000000000000001a6d0000000000000000000000000000000000000000000000000000000000002ac2",
"proof": "0x00cd9faf08b496bc4ff57a76d69719938a872d4b95f2f638b5f21f2b0cef825606bc14032748e2a86a8dadb00de79f88c650fa2f83813e4f69661b15600d09e9f328b7332dddaeb8dc27519c906bea438929e5474fe76dc940ea6ec3b50ce898a54c339d1c1ece67e746335652d5afb0d950d19960ef34dc7885d99296cad3b1385f9c161ab54408afffb8143708737c89c54988b3512478b79affac241bd08ba4dc75da105764b63b6101fdf06cdbd136a371f932d769c2cd6ba4b699fa61a2bfb5ad5215b4b64f1388484291240faf87c09a04d8ee2a7c47d3f68c6509ab172fecfffd02a2edee4e7deaf93557e22bc99fd3d7f2bf1af15b40b7d09685e6b8d528a122"
}
Note: EVM-compatible proofs e.g., Groth16, are more computationally intensive to generate but are required for on-chain verification. See here for more detailed explanations on the types of proofs Ziren offers.
Local proving is enabled by default as ZKM_PROVER=network in your .env file. It is recommended that you use ZKM’s Prover Network for heavier workloads. To enable network proving, following the instructions listed here and update your .env file:
#![allow(unused)] fn main() { ZKM_PROVER=network ZKM_PRIVATE_KEY=<your_key> SSL_CERT_PATH=<path_to_cert> SSL_KEY_PATH=<path_to_key> }
Verifying a proof on-chain
Once you’ve generated a proof, you can compile the verifier contract. To compile and execute all Foundry Solidity test files in the contracts directory:
#![allow(unused)] fn main() { cd contracts forge test }
Foundry will detect and run all test contracts to verify that
- The proof fixtures in
./contracts/src/fixtures(either PLONK or Groth16) are correctly accepted or rejected. - The Solidity verifier contracts
ZKMVerifierGroth16.solandZKMVerifierPlonk.solbehave correctly. - The application contract
Fibonacci.solintegrates correctly with the verifiers.
An example output with all passing tests:
[⠊] Compiling...
[⠊] Compiling 32 files with Solc 0.8.28
[⠒] Solc 0.8.28 finished in 902.25ms
Compiler run successful!
Ran 2 tests for test/Fibonacci.t.sol:FibonacciGroth16Test
[PASS] testRevert_InvalidFibonacciProof() (gas: 28279)
[PASS] test_ValidFibonacciProof() (gas: 28825)
Suite result: ok. 2 passed; 0 failed; 0 skipped; finished in 1.37ms (617.07µs CPU time)
Ran 2 tests for test/Fibonacci.t.sol:FibonacciPlonkTest
[PASS] testRevert_InvalidFibonacciProof() (gas: 29569)
[PASS] test_ValidFibonacciProof() (gas: 29995)
Suite result: ok. 2 passed; 0 failed; 0 skipped; finished in 1.42ms (608.57µs CPU time)
Ran 2 tests for test/ZKMVerifierGroth16.t.sol:ZKMVerifierGroth16Test
[PASS] test_RevertVerifyProof_WhenGroth16() (gas: 209970)
[PASS] test_VerifyProof_WhenGroth16() (gas: 209948)
Suite result: ok. 2 passed; 0 failed; 0 skipped; finished in 9.24ms (15.99ms CPU time)
Ran 2 tests for test/ZKMVerifierPlonk.t.sol:ZKMVerifierPlonkTest
[PASS] test_RevertVerifyProof_WhenPlonk() (gas: 282131)
[PASS] test_VerifyProof_WhenPlonk() (gas: 282132)
Suite result: ok. 2 passed; 0 failed; 0 skipped; finished in 10.94ms (18.99ms CPU time)
Ran 4 test suites in 11.53ms (22.97ms CPU time): 8 tests passed, 0 failed, 0 skipped (8 total tests)
Once you’ve compiled the verifier contracts, you can deploy it to Sepolia or another EVM-compatible test network:
#![allow(unused)] fn main() { forge script script/ZKMVerifierGroth16.s.sol:ZKMVerifierGroth16Script \ --rpc-url <RPC_URL> \ --private-key <YOUR_PRIVATE_KEY> --broadcast }
<RPC_URL>: Replace with your RPC endpoint (e.g., from Alchemy or Infura)<YOUR_PRIVATE_KEY>: Replace with the private key of your wallet
The command executes the ZKMVerifierGroth16Script script, which deploys the ZKMVerifierGroth16 contract to the network.
To deploy to a different verifier, e.g., PLONK, replace the script name accordingly:
#![allow(unused)] fn main() { forge script script/ZKMVerifierPlonk.s.sol:ZKMVerifierPlonkScript \ --rpc-url <RPC_URL> \ --private-key <YOUR_PRIVATE_KEY> --broadcast }
The successful deployment output for a Groth16 proof on Sepolia:
Script ran successfully.
## Setting up 1 EVM.
==========================
Chain 11155111
Estimated gas price: 0.002525776 gwei
Estimated total gas used for script: 3185830
Estimated amount required: 0.00000804669295408 ETH
==========================
##### sepolia
✅ [Success] Hash: 0x2143e3239579833092460969bffe71b8f2b8cc8cc360a34f01203c22bc465abb
Contract Address: 0x750Ad1b02000F6cC9Bc4E1F2dE2a85534D681841
Block: 8664583
Paid: 0.000004480767952712 ETH (2450639 gas * 0.001828408 gwei)
✅ Sequence #1 on sepolia | Total Paid: 0.000004480767952712 ETH (2450639 gas * avg 0.001828408 gwei)
==========================
ONCHAIN EXECUTION COMPLETE & SUCCESSFUL.
Transactions saved to: /zkm-project-template/contracts/broadcast/ZKMVerifierGroth16.s.sol/11155111/run-latest.json
Sensitive values saved to: /zkm-project-template/contracts/cache/ZKMVerifierGroth16.s.sol/11155111/run-latest.json
Performance
Metrics
To evaluate a zkVM’s performance, two primary metrics are considered: Efficiency and Cost.
Efficiency
The Efficiency, or cycles per instruction, means how many cycles the zkVM can prove in one second. One cycle is usually mapped to one MIPS instruction in the zkVM.
For each MIPS instruction in a shard, it goes through two main phases: the execution phase and the proving phase (to generate the proof).
In the execution phase, the MIPS VM (Emulator) reads the instruction at the program counter (PC) from the program image and executes it to generate execution traces (events). These traces are converted into a matrix for the proving phase. The number of traces depends on the program's instruction sequence - the shorter the sequence, the more efficient the execution and proving.
In the proving phase, the Ziren prover uses a Polynomial Commitment Scheme (PCS) — specifically FRI — to commit the execution traces. The proving complexity is determined by the matrix size of the trace table.
Therefore, the instruction sequence size and prover efficiency directly impact overall proving performance.
Cost
Proving cost is a more comprehensive metric that measures the total expense of proving a specific program. It can be approximated as: Prover Efficiency * Unit, Where Prover Efficiency reflects execution performance, and Unit Price refers to the cost per second of the server running the prover.
For example, ethproofs.org provides a platform for all zkVMs to submit their Ethereum mainnet block proofs, which includes the proof size, proving time and proving cost per Mgas (Efficiency * Unit / GasUsed, where the GasUsed is of unit Mgas).
zkVM benchmarks
To facilitate the fairest possible comparison among different zkVMs, we provide the zkvm-benchmarks suite, enabling anyone to reproduce the performance data.
Performance of Ziren
The performance of Ziren on an AWS r6a.8xlarge instance, a CPU-based server, is presented below:
Note that all the time is of unit millisecond. Define Rate = 100*(SP1 - Ziren)/Ziren.
Fibonacci
| n | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 100 | 1691 | 6478 | 1947 | 5828 | 199.33 |
| 1000 | 3291 | 8037 | 1933 | 5728 | 196.32 |
| 10000 | 12881 | 44239 | 2972 | 7932 | 166.89 |
| 58218 | 64648 | 223534 | 14985 | 31063 | 107.29 |
sha2
| Byte Length | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 32 | 3307 | 7866 | 1927 | 5931 | 207.78 |
| 256 | 6540 | 8318 | 1913 | 5872 | 206.95 |
| 512 | 6504 | 11530 | 1970 | 5970 | 203.04 |
| 1024 | 12972 | 13434 | 2192 | 6489 | 196.03 |
| 2048 | 25898 | 22774 | 2975 | 7686 | 158.35 |
sha3
| Byte Length | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 32 | 3303 | 7891 | 1972 | 5942 | 201.31 |
| 256 | 6487 | 10636 | 2267 | 5909 | 160.65 |
| 512 | 12965 | 13015 | 2225 | 6580 | 195.73 |
| 1024 | 13002 | 21044 | 3283 | 7612 | 131.86 |
| 2048 | 26014 | 43249 | 4923 | 10087 | 104.89 |
Proving with precompile:
| Byte Length | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|
| 32 | 646 | 980 | 51.70 |
| 256 | 634 | 990 | 56.15 |
| 512 | 731 | 993 | 35.84 |
| 1024 | 755 | 1034 | 36.95 |
| 2048 | 976 | 1257 | 28.79 |
big-memory
| Value | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 5 | 78486 | 199344 | 21218 | 36927 | 74.03 |
sha2-chain
| Iterations | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 230 | 53979 | 141451 | 8756 | 15850 | 81.01 |
| 460 | 104584 | 321358 | 17789 | 31799 | 78.75 |
sha3-chain
| Iterations | ROVM 2.0.1 | Ziren 0.3 | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|---|---|
| 230 | 208734 | 718678 | 36205 | 39987 | 10.44 |
| 460 | 417773 | 1358248 | 68488 | 68790 | 0.44 |
Proving with precompile:
| Iterations | Ziren 1.0 | SP1 4.1.1 | Rate |
|---|---|---|---|
| 230 | 3491 | 4277 | 22.51 |
| 460 | 6471 | 7924 | 22.45 |
Use Cases: GOAT Network
GOAT Network is a Bitcoin L2, the first L2 to be implemented on ZKM’s Entangled Network. As a full-stack Bitcoin-based zkRollup, GOAT leverages Ziren (ZKM’s in-house zkVM) to enable real-time proving, trustless bridging, and Bitcoin-native settlement.
Proving Block Execution
Ziren is used to generate ZK proofs for individual blocks processed by GOAT’s sequencers. Each proof demonstrates that a block was executed correctly and that its resulting state transitions are valid. To amortize costs, proofs are generated over a specific period rather than for each transaction individually.
The proof contains the hash of the associated block, root hash of the sequencer set and new state root. These values are bundled and submitted to the Bitcoin L1. The block hash and the root hash serve as public inputs to the ZK circuit and are required to match the corresponding values that have already been posted on Bitcoin L1.
Real-Time Proving & Peg-Out Proofs
Ziren enables the generation of proofs in real time for every block on GOAT, which powers the BitVM2 bridge used for withdrawals during the peg-out process. This capability eliminates the delays that can otherwise occur during withdrawals, allowing funds to be released in sync with block production rather than requiring days (or even weeks) of waiting.
During the peg-out process, operators act as provers to generate ZK proofs for peg-out transactions. Challengers can contest invalid proofs within an optimistic challenge window.
The proof generation pipeline for peg-outs consists of several stages:
- Root Prover: Computes core execution trace.
- Aggregation Prover: Compresses multiple core proofs.
- SNARK Prover: Generates Groth16 proofs (allowing for an EVM-compatible format) for Bitcoin verification.
This architecture enables low-latency withdrawals and the rapid inclusion of new blocks. View proofs being generated in real-time for GOAT, including details for each proof in the pipeline here: https://bitvm2.testnet3.goat.network/proof.
Proof Verification via BitVM Paradigm
Once generated, proof commitments are submitted to a BitVM2-anchored covenant on Bitcoin L1 and is verified via BitVM2’s fraud-proof challenge mechanism. Verification involves confirming that the public inputs of the ZK proof correspond to a valid transaction on Bitcoin L1 and that this transaction is finalized within a sufficiently long proof-of-work chain.
All ZK proofs are tied to the committed state; any attempt to manipulate the state would produce a different public input, which would cause verification to fail. Both the L2 state and its execution are fully auditable by any participant.
Transaction Lifecycle
The following is an overview of the transaction lifecycle on GOAT and Ziren’s role in it:
- A user first submits a transaction to the L2.
- The sequencer batches and executes transactions into an L2 block, which is then processed by Ziren.
- Ziren generates a ZK proof that attests to the correctness of the block’s execution and its state transitions.
- The ZK proof generated by Ziren, together with the state commitment, are submitted to a BitVM2-anchored covenant on the Bitcoin L1.
Entangled Rollup Use Case
ZKM’s primary use case is Entangled Network, using validity proofs to verify cross-chain messaging between L2s without implementing the architecture of a bridge. In this way, security is natively inherited by the underlying L1 e.g., Bitcoin in the case of GOAT, as opposed to a third-party bridge which has its own security tradeoffs such as custodial risk, use of wrapped assets, additional trust assumptions, and multisig control.
By treating the L2s as bridges, all L2s part of the Entangled Rollup Network can share state, liquidity and execution. Ziren is used to generate valid proofs of state transitions, proving the execution of blocks in the L2s to be verified on their underlying L2s.
Ziren underpins GOAT’s cross-chain interoperability through the Entangled Rollup Network:
- Rollup proofs double as bridge receipts—a single validity proof can verify execution on one L2 and unlock assets on another.
- Enables native asset transfers across incompatible chains (e.g., Bitcoin ↔ Ethereum L2s).
- Validity proofs ensure L1-final settlement across chains, preserving each chain’s native security.
Read more about how Entangled Network enables native assets and unified liquidity between (even incompatible) chains here.
.
Independent Evaluations
- Ziren (v1.1.4) underwent an independent evaluation by Prooflab.
Recommended use cases for Ziren as noted in the report are Bitcoin L2 implementations, hybrid (combining ZK and optimistic) rollups, zkML verification and cross-chain applications. View the full evaluation report for Ziren here.
- Ziren takes a deliberate architectural bet on MIPS32, prioritizing instruction regularity and constraint uniformity over RISC-V ecosystem convenience (zkVM level instruction efficiency)
Understanding zkVM: From Research to Practice
MIPS VM
Ziren is a verifiable computation infrastructure based on the MIPS32, specifically designed to provide zero-knowledge proof generation for programs written in Rust. This enhances project auditing and the efficiency of security verification. Focusing on the extensive design experience of MIPS, Ziren adopts the MIPS32r2 instruction set. MIPS VM, one of the core components of Ziren, is the execution framework of MIPS32r2 instructions. Below we will briefly introduce the advantages of MIPS32r2 over RV32IM and the execution flow of MIPS VM.
Advantages of MIPS32r2 over RV32IM
1. MIPS32r2 is more consistent and offers more complex opcodes
- The J/JAL instructions support jump ranges of up to 256MiB, offering greater flexibility for large-scale data processing and complex control flow scenarios.
- MIPS32r2 has rich set of bit manipulation instructions and additional conditional move instructions (such as MOVZ and MOVN) that ensure precise data handling.
- MIPS32r2 has integer multiply-add/sub instructions, which can improve arithmetic computation efficiency.
- MIPS32r2 has SEH and SEB sign extension instructions, which make it very convenient to perform sign extension operations on char and short type data.
2. MIPS32r2 has a more established ecosystem
- All instructions in MIPS32r2, as a whole, have been very mature and widely used for more than 20 years. There will be no compatibility issues between ISA modules. And there will be no turmoil caused by manufacturer disputes.
- MIPS has been successfully applied to Optimism's Fraud Proof VM
Execution Flow of MIPS VM
The execution flow of MIPS VM is as follows:
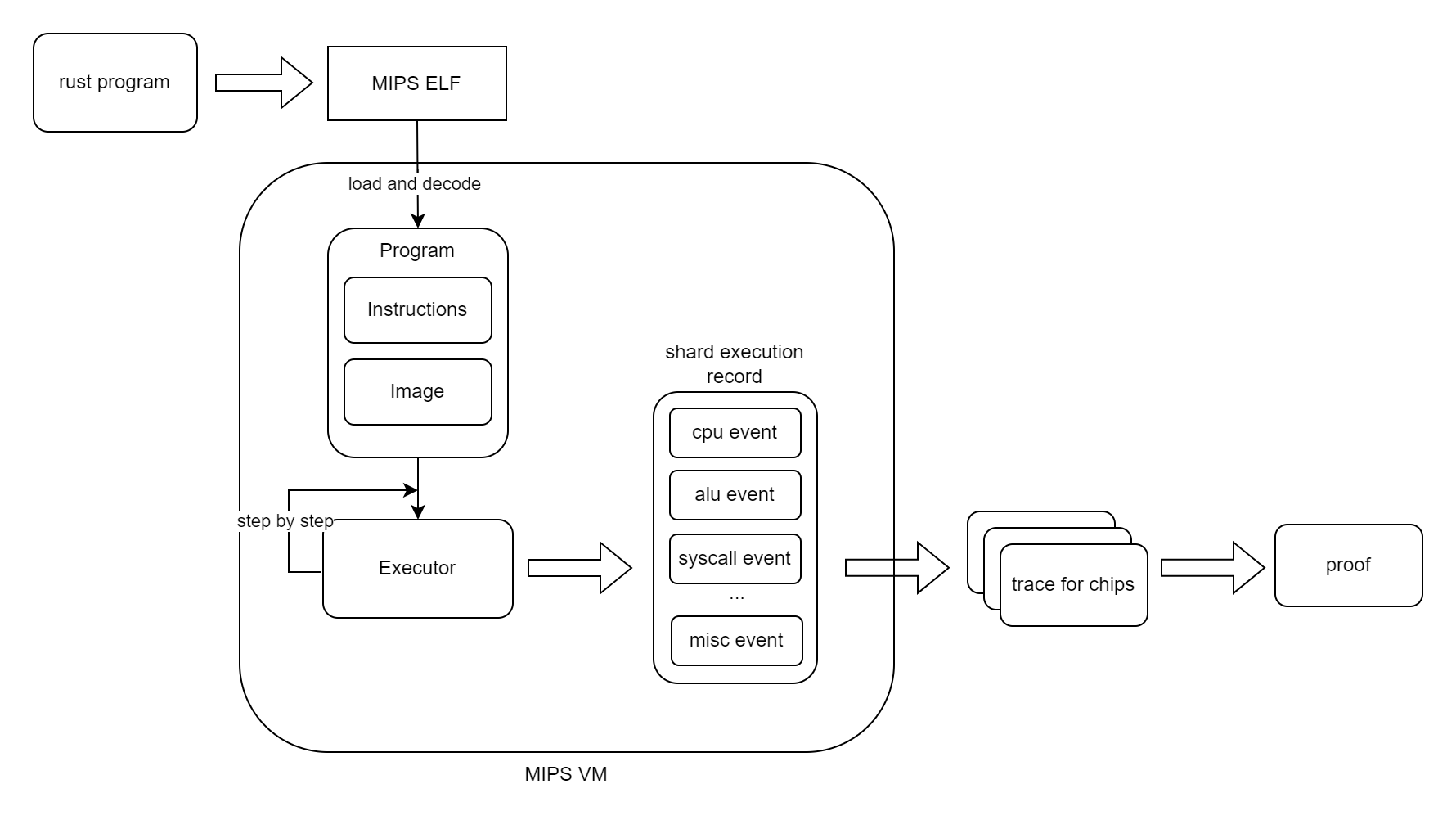 Before the execution process of MIPS VM, a Rust program written by the developer is first transformed by a dedicated compiler into the MIPS instruction set, generating a corresponding ELF binary file. This process accurately maps the high-level logic of the program to low-level instructions, laying a solid foundation for subsequent verification.
Before the execution process of MIPS VM, a Rust program written by the developer is first transformed by a dedicated compiler into the MIPS instruction set, generating a corresponding ELF binary file. This process accurately maps the high-level logic of the program to low-level instructions, laying a solid foundation for subsequent verification.
MIPS VM employs a specially designed executor to simulate the execution of the ELF file:
- First,the ELF code is loaded into Program, where all data is loaded into the memory image, and all the code is decoded and added into the Instruction List.
- Then, MIPS VM executes the Instruction and update the ISA states step by step, which is started from the entry point of the ELF and ended with exit condition is triggered. A complete execution record with different type of events is recorded in this process. The whole program will be divided into several shards based on the shape of the execution record.
After the execution process of MIPS VM, the execution record will be used by the prover to generate zero-knowledge proof:
- The events recorded in execution record will be used to generate different traces by different chips.
- This traces serve as the core data for generating the zero-knowledge proof, ensuring that the proof accurately reflects the real execution of the compiled program.
Memory Layout for guest program
The memory layout for guest program is controlled by VM, runtime and toolchain.
Rust guest program
Two kinds of allocators are provided to rust guest program
- bump allocator: both normal memory and program I/O is allocated from the heap. And the heap address is always increased and cannot be reused.
| Section | Start | Size | Access | Controlled-by |
|---|---|---|---|---|
| registers | 0x00 | 36 | rw | VM |
| Stack | 0x7f000000 | (stack grows down) | rw | runtime |
| Code | ||||
| .text | .text size | ro | toolchain | |
| .rodata | .rodata size | ro | toolchain | |
| .eh_frame | .eh_frame size | ro | toolchain | |
| .bss | .bss size | ro | toolchain | |
| Heap (contains program I/O) | _end | 0x7f000000 - _end | rw | runtime |
- embedded allocator: Program I/O address space is reserved and split from heap address space. A TLS heap is used for heap management.
| Section | Start | Size | Access | Controlled-by |
|---|---|---|---|---|
| registers | 0x00 | 36 | rw | VM |
| Stack | 0x7f000000 | (stack grows down) | rw | runtime |
| Code | ||||
| .text | .text size | ro | toolchain | |
| .rodata | .rodata size | ro | toolchain | |
| .eh_frame | .eh_frame size | ro | toolchain | |
| .bss | .bss size | ro | toolchain | |
| Program I/O | 0x3f000000 | 0x40000000 | rw | runtime |
| Heap | _end | 0x3f000000 - _end | rw | runtime |
Go guest program
Go guest program is similar to embedded-mode rust guest program, except that the initial args is set by VM at the top of the stack. The memory layout is as follows:
| Section | Start | Size | Access | Controlled-by |
|---|---|---|---|---|
| registers | 0x00 | 36 | rw | VM |
| Stack | 0x7f000000 | (stack grows down) | rw | runtime |
| Initial args | 0x7effc000 | 0x4000 | ro | VM |
| Code | ||||
| .text | .text size | ro | toolchain | |
| .rodata | .rodata size | ro | toolchain | |
| .eh_frame | .eh_frame size | ro | toolchain | |
| .bss | .bss size | ro | toolchain | |
| Program I/O | 0x3f000000 | 0x40000000 | rw | runtime |
| Heap | _end | 0x3f000000 - _end | rw | runtime |
MIPS ISA
The Opcode enum organizes MIPS instructions into several functional categories, each serving a specific role in the instruction set:
#![allow(unused)] fn main() { pub enum Opcode { // ALU ADD = 0, // ADDSUB SUB = 1, // ADDSUB MUL = 2, // MUL MULT = 3, // MUL MULTU = 4, // MUL DIV = 5, // DIVREM DIVU = 6, // DIVREM MOD = 7, // DIVREM MODU = 8, // DIVREM SLL = 9, // SLL SRL = 10, // SR SRA = 11, // SR ROR = 12, // SR SLT = 13, // LT SLTU = 14, // LT AND = 15, // BITWISE OR = 16, // BITWISE XOR = 17, // BITWISE NOR = 18, // BITWISE CLZ = 19, // CLO_CLZ CLO = 20, // CLO_CLZ // Control FLow BEQ = 21, // BRANCH BGEZ = 22, // BRANCH BGTZ = 23, // BRANCH BLEZ = 24, // BRANCH BLTZ = 25, // BRANCH BNE = 26, // BRANCH Jump = 27, // JUMP Jumpi = 28, // JUMP JumpDirect = 29, // JUMP SYSCALL = 30, // SYSCALL // Memory Op LB = 31, // LOAD LBU = 32, // LOAD LH = 33, // LOAD LHU = 34, // LOAD LW = 35, // LOAD LWL = 36, // LOAD LWR = 37, // LOAD LL = 38, // LOAD SB = 39, // STORE SH = 40, // STORE SW = 41, // STORE SWL = 42, // STORE SWR = 43, // STORE SC = 44, // STORE // Misc INS = 45, // INS MADDU = 46, // MADDSUB MSUBU = 47, // MADDSUB MADD = 48, // MADDSUB MSUB = 49, // MADDSUB MEQ = 50, // MOVCOND MNE = 51, // MOVCOND WSBH = 52, // WSBH EXT = 53, // EXT TEQ = 54, // TEQ SEXT = 55, // SEXT // Syscall UNIMPL = 0xff, } }
All MIPS instructions can be divided into the following taxonomies:
ALU Operators
This category includes the fundamental arithmetic logical operations and count operations. It covers addition (ADD) and subtraction (SUB), several multiplication and division variants (MULT, MULTU, MUL, DIV, DIVU), as well as bit shifting and rotation operations (SLL, SRL, SRA, ROR), comparison operations like set less than (SLT, SLTU) a range of bitwise logical operations (AND, OR, XOR, NOR) and count operations like CLZ counts the number of leading zeros, while CLO counts the number of leading ones. These operations are useful in bit-level data analysis.
Memory Operations
This category is dedicated to moving data between memory and registers. It contains a comprehensive set of load instructions—such as LH (load halfword), LWL (load word left), LW (load word), LB (load byte), LBU (load byte unsigned), LHU (load halfword unsigned), LWR (load word right), and LL (load linked)—as well as corresponding store instructions like SB (store byte), SH (store halfword), SWL (store word left), SW (store word), SWR (store word right), and SC (store conditional). These operations ensure that data is correctly and efficiently read from or written to memory.
Branching Instructions
Instructions BEQ (branch if equal), BGEZ (branch if greater than or equal to zero), BGTZ (branch if greater than zero), BLEZ (branch if less than or equal to zero), BLTZ (branch if less than zero), and BNE (branch if not equal) are used to change the flow of execution based on comparisons. These instructions are vital for implementing loops, conditionals, and other control structures.
Jump Instructions
Jump-related instructions, including Jump, Jumpi, and JumpDirect, are responsible for altering the execution flow by redirecting it to different parts of the program. They are used for implementing function calls, loops, and other control structures that require non-sequential execution, ensuring that the program can navigate its code dynamically.
Syscall Instructions
SYSCALL triggers a system call, allowing the program to request services from the zkvm operating system. The service can be a precompile computation, such as do sha extend operation by SHA_EXTEND precompile. it also can be input/output operation such as SYSHINTREADYSHINTREAD and WRITE.
Misc Instructions
This category includes other instructions. TEQ is typically used to test equality conditions between registers. MADDU/MSUBU is used for multiply accumulation. SEB/SEH is for data sign extended. EXT/INS is for bits extraction and insertion.
Supported instructions
The support instructions are as follows:
| instruction | Op [31:26] | rs [25:21] | rt [20:16] | rd [15:11] | shamt [10:6] | func [5:0] | function |
|---|---|---|---|---|---|---|---|
| ADD | 000000 | rs | rt | rd | 00000 | 100000 | rd = rs + rt |
| ADDI | 001000 | rs | rt | imm | imm | imm | rt = rs + sext(imm) |
| ADDIU | 001001 | rs | rt | imm | imm | imm | rt = rs + sext(imm) |
| ADDU | 000000 | rs | rt | rd | 00000 | 100001 | rd = rs + rt |
| AND | 000000 | rs | rt | rd | 00000 | 100100 | rd = rs & rt |
| ANDI | 001100 | rs | rt | imm | imm | imm | rt = rs & zext(imm) |
| BEQ | 000100 | rs | rt | offset | offset | offset | PC = PC + sext(offset<<2), if rs == rt |
| BGEZ | 000001 | rs | 00001 | offset | offset | offset | PC = PC + sext(offset<<2), if rs >= 0 |
| BGTZ | 000111 | rs | 00000 | offset | offset | offset | PC = PC + sext(offset<<2), if rs > 0 |
| BLEZ | 000110 | rs | 00000 | offset | offset | offset | PC = PC + sext(offset<<2), if rs <= 0 |
| BLTZ | 000001 | rs | 00000 | offset | offset | offset | PC = PC + sext(offset<<2), if rs < 0 |
| BNE | 000101 | rs | rt | offset | offset | offset | PC = PC + sext(offset<<2), if rs != rt |
| CLO | 011100 | rs | rt | rd | 00000 | 100001 | rd = count_leading_ones(rs) |
| CLZ | 011100 | rs | rt | rd | 00000 | 100000 | rd = count_leading_zeros(rs) |
| DIV | 000000 | rs | rt | 00000 | 00000 | 011010 | (hi, lo) = (rs%rt, rs/ rt), signed |
| DIVU | 000000 | rs | rt | 00000 | 00000 | 011011 | (hi, lo) = (rs%rt, rs/rt), unsigned |
| J | 000010 | instr_index | instr_index | instr_index | instr_index | instr_index | PC = PC[GPRLEN-1..28] || instr_index || 00 |
| JAL | 000011 | instr_index | instr_index | instr_index | instr_index | instr_index | r31 = PC + 8, PC = PC[GPRLEN-1..28] || instr_index || 00 |
| JALR | 000000 | rs | 00000 | rd | hint | 001001 | rd = PC + 8, PC = rs |
| JR | 000000 | rs | 00000 | 00000 | hint | 001000 | PC = rs |
| LB | 100000 | base | rt | offset | offset | offset | rt = sext(mem_byte(base + offset)) |
| LBU | 100100 | base | rt | offset | offset | offset | rt = zext(mem_byte(base + offset)) |
| LH | 100001 | base | rt | offset | offset | offset | rt = sext(mem_halfword(base + offset)) |
| LHU | 100101 | base | rt | offset | offset | offset | rt = zext(mem_halfword(base + offset)) |
| LL | 110000 | base | rt | offset | offset | offset | rt = mem_word(base + offset) |
| LUI | 001111 | 00000 | rt | imm | imm | imm | rt = imm<<16 |
| LW | 100011 | base | rt | offset | offset | offset | rt = mem_word(base + offset) |
| LWL | 100010 | base | rt | offset | offset | offset | rt = rt merge most significant part of mem(base+offset) |
| LWR | 100110 | base | rt | offset | offset | offset | rt = rt merge least significant part of mem(base+offset) |
| MFHI | 000000 | 00000 | 00000 | rd | 00000 | 010000 | rd = hi |
| MFLO | 000000 | 00000 | 00000 | rd | 00000 | 010010 | rd = lo |
| MOVN | 000000 | rs | rt | rd | 00000 | 001011 | rd = rs, if rt != 0 |
| MOVZ | 000000 | rs | rt | rd | 00000 | 001010 | rd = rs, if rt == 0 |
| MTHI | 000000 | rs | 00000 | 00000 | 00000 | 010001 | hi = rs |
| MTLO | 000000 | rs | 00000 | 00000 | 00000 | 010011 | lo = rs |
| MUL | 011100 | rs | rt | rd | 00000 | 000010 | rd = rs * rt |
| MULT | 000000 | rs | rt | 00000 | 00000 | 011000 | (hi, lo) = rs * rt |
| MULTU | 000000 | rs | rt | 00000 | 00000 | 011001 | (hi, lo) = rs * rt |
| NOR | 000000 | rs | rt | rd | 00000 | 100111 | rd = !rs | rt |
| OR | 000000 | rs | rt | rd | 00000 | 100101 | rd = rs | rt |
| ORI | 001101 | rs | rt | imm | imm | imm | rd = rs | zext(imm) |
| SB | 101000 | base | rt | offset | offset | offset | mem_byte(base + offset) = rt |
| SC | 111000 | base | rt | offset | offset | offset | mem_word(base + offset) = rt, rt = 1, if atomic update, else rt = 0 |
| SH | 101001 | base | rt | offset | offset | offset | mem_halfword(base + offset) = rt |
| SLL | 000000 | 00000 | rt | rd | sa | 000000 | rd = rt<<sa |
| SLLV | 000000 | rs | rt | rd | 00000 | 000100 | rd = rt << rs[4:0] |
| SLT | 000000 | rs | rt | rd | 00000 | 101010 | rd = rs < rt |
| SLTI | 001010 | rs | rt | imm | imm | imm | rt = rs < sext(imm) |
| SLTIU | 001011 | rs | rt | imm | imm | imm | rt = rs < sext(imm) |
| SLTU | 000000 | rs | rt | rd | 00000 | 101011 | rd = rs < rt |
| SRA | 000000 | 00000 | rt | rd | sa | 000011 | rd = rt >> sa |
| SRAV | 000000 | rs | rt | rd | 00000 | 000111 | rd = rt >> rs[4:0] |
| SYNC | 000000 | 00000 | 00000 | 00000 | stype | 001111 | sync (nop) |
| SRL | 000000 | 00000 | rt | rd | sa | 000010 | rd = rt >> sa |
| SRLV | 000000 | rs | rt | rd | 00000 | 000110 | rd = rt >> rs[4:0] |
| SUB | 000000 | rs | rt | rd | 00000 | 100010 | rd = rs - rt |
| SUBU | 000000 | rs | rt | rd | 00000 | 100011 | rd = rs - rt |
| SW | 101011 | base | rt | offset | offset | offset | mem_word(base + offset) = rt |
| SWL | 101010 | base | rt | offset | offset | offset | store most significant part of rt |
| SWR | 101110 | base | rt | offset | offset | offset | store least significant part of rt |
| SYSCALL | 000000 | code | code | code | code | 001100 | syscall |
| XOR | 000000 | rs | rt | rd | 00000 | 100110 | rd = rs ^ rt |
| XORI | 001110 | rs | rt | imm | imm | imm | rd = rs ^ zext(imm) |
| BAL | 000001 | 00000 | 10001 | offset | offset | offset | RA = PC + 8, PC = PC + sign_extend(offset || 00) |
| SYNCI | 000001 | base | 11111 | offset | offset | offset | sync (nop) |
| PREF | 110011 | base | hint | offset | offset | offset | prefetch(nop) |
| TEQ | 000000 | rs | rt | code | code | 110100 | trap,if rs == rt |
| ROTR | 000000 | 00001 | rt | rd | sa | 000010 | rd = rotate_right(rt, sa) |
| ROTRV | 000000 | rs | rt | rd | 00001 | 000110 | rd = rotate_right(rt, rs[4:0]) |
| WSBH | 011111 | 00000 | rt | rd | 00010 | 100000 | rd = swaphalf(rt) |
| EXT | 011111 | rs | rt | msbd | lsb | 000000 | rt = rs[msbd+lsb..lsb] |
| SEH | 011111 | 00000 | rt | rd | 11000 | 100000 | rd = signExtend(rt[15..0]) |
| SEB | 011111 | 00000 | rt | rd | 10000 | 100000 | rd = signExtend(rt[7..0]) |
| INS | 011111 | rs | rt | msb | lsb | 000100 | rt = rt[32:msb+1] || rs[msb+1-lsb : 0] || rt[lsb-1:0] |
| MADDU | 011100 | rs | rt | 00000 | 00000 | 000001 | (hi, lo) = rs * rt + (hi,lo) |
| MSUBU | 011100 | rs | rt | 00000 | 00000 | 000101 | (hi, lo) = (hi,lo) - rs * rt |
Supported syscalls
| syscall number | function |
|---|---|
| SYSHINTLEN = 0x00_00_00F0, | Return length of current input data. |
| SYSHINTREAD = 0x00_00_00F1, | Read current input data. |
| SYSVERIFY = 0x00_00_00F2, | Verify pre-compile program. |
| HALT = 0x00_00_0000, | Halts the program. |
| WRITE = 0x00_00_0002, | Write to the output buffer. |
| ENTER_UNCONSTRAINED = 0x00_00_0003, | Enter unconstrained block. |
| EXIT_UNCONSTRAINED = 0x00_00_0004, | Exit unconstrained block. |
| SHA_EXTEND = 0x30_01_0005, | Executes the SHA_EXTEND precompile. |
| SHA_COMPRESS = 0x01_01_0006, | Executes the SHA_COMPRESS precompile. |
| ED_ADD = 0x01_01_0007, | Executes the ED_ADD precompile. |
| ED_DECOMPRESS = 0x00_01_0008, | Executes the ED_DECOMPRESS precompile. |
| KECCAK_SPONGE = 0x01_01_0009, | Executes the KECCAK_SPONGE precompile. |
| SECP256K1_ADD = 0x01_01_000A, | Executes the SECP256K1_ADD precompile. |
| SECP256K1_DOUBLE = 0x00_01_000B, | Executes the SECP256K1_DOUBLE precompile. |
| SECP256K1_DECOMPRESS = 0x00_01_000C, | Executes the SECP256K1_DECOMPRESS precompile. |
| BN254_ADD = 0x01_01_000E, | Executes the BN254_ADD precompile. |
| BN254_DOUBLE = 0x00_01_000F, | Executes the BN254_DOUBLE precompile. |
| COMMIT = 0x00_00_0010, | Executes the COMMIT precompile. |
| COMMIT_DEFERRED_PROOFS = 0x00_00_001A, | Executes the COMMIT_DEFERRED_PROOFS precompile. |
| VERIFY_ZKM_PROOF = 0x00_00_001B, | Executes the VERIFY_ZKM_PROOF precompile. |
| BLS12381_DECOMPRESS = 0x00_01_001C, | Executes the BLS12381_DECOMPRESS precompile. |
| UINT256_MUL = 0x01_01_001D, | Executes the UINT256_MUL precompile. |
| U256XU2048_MUL = 0x01_01_002F, | Executes the U256XU2048_MUL precompile. |
| BLS12381_ADD = 0x01_01_001E, | Executes the BLS12381_ADD precompile. |
| BLS12381_DOUBLE = 0x00_01_001F, | Executes the BLS12381_DOUBLE precompile. |
| BLS12381_FP_ADD = 0x01_01_0020, | Executes the BLS12381_FP_ADD precompile. |
| BLS12381_FP_SUB = 0x01_01_0021, | Executes the BLS12381_FP_SUB precompile. |
| BLS12381_FP_MUL = 0x01_01_0022, | Executes the BLS12381_FP_MUL precompile. |
| BLS12381_FP2_ADD = 0x01_01_0023, | Executes the BLS12381_FP2_ADD precompile. |
| BLS12381_FP2_SUB = 0x01_01_0024, | Executes the BLS12381_FP2_SUB precompile. |
| BLS12381_FP2_MUL = 0x01_01_0025, | Executes the BLS12381_FP2_MUL precompile. |
| BN254_FP_ADD = 0x01_01_0026, | Executes the BN254_FP_ADD precompile. |
| BN254_FP_SUB = 0x01_01_0027, | Executes the BN254_FP_SUB precompile. |
| BN254_FP_MUL = 0x01_01_0028, | Executes the BN254_FP_MUL precompile. |
| BN254_FP2_ADD = 0x01_01_0029, | Executes the BN254_FP2_ADD precompile. |
| BN254_FP2_SUB = 0x01_01_002A, | Executes the BN254_FP2_SUB precompile. |
| BN254_FP2_MUL = 0x01_01_002B, | Executes the BN254_FP2_MUL precompile. |
| SECP256R1_ADD = 0x01_01_002C, | Executes the SECP256R1_ADD precompile. |
| SECP256R1_DOUBLE = 0x00_01_002D, | Executes the SECP256R1_DOUBLE precompile. |
| SECP256R1_DECOMPRESS = 0x00_01_002E, | Executes the SECP256R1_DECOMPRESS precompile. |
| POSEIDON2_PERMUTE = 0x00_01_0030, | Executes the POSEIDON2_PERMUTE precompile. |
| SYS_MMAP = 4210, | Executes the Linux MMAP API precompile. |
| SYS_MMAP2 = 4090, | Executes the Linux MMAP2 API precompile. |
| SYS_BRK = 4045, | Executes the Linux BRK API precompile. |
| SYS_CLONE = 4120, | Executes the Linux CLONE API precompile. |
| SYS_EXIT_GROUP = 4246, | Executes the Linux EXIT GROUP API precompile. |
| SYS_READ = 4003, | Executes the Linux READ API precompile. |
| SYS_WRITE = 4004, | Executes the Linux WRITE API precompile. |
| SYS_FCNTL = 4055, | Executes the Linux FCNTL API precompile. |
| SYS_NOP = 4000, | Executes the NOP API precompile. |
All the unimplemented Linux syscalls API are treated as SYS_NOP.
Linux ABI Support
This document describes how Ziren supports the Linux ABI inside its MIPS zkVM, covering execution, proving, and cross-shard verification.
Overview
Ziren runs MIPS guest programs compiled against a Linux userspace ABI. The guest issues SYSCALL instructions just like a real MIPS/Linux process. The zkVM intercepts these and either:
- Executes the syscall in the host executor (producing a concrete result), then
- Proves that the result is correct via AIR constraints in the
SysLinuxChip.
The guest never touches real kernel code. The zkVM emulates a minimal Linux kernel that supports memory management, basic I/O, and process lifecycle — enough to run programs compiled with standard C/Go/Rust toolchains targeting MIPS.
Architecture
Guest Program (MIPS binary)
|
SYSCALL (V0 = syscall number)
|
v
+-------------------------------+
| Executor |
| |
| execute_operation() |
| -> SyscallCode::from_u32() |
| -> get_syscall() |
| -> handler.execute() |
| -> emit_syscall_event() |
+-------------------------------+
| |
LinuxEvent LinuxEvent
| |
v v
+--------------------+ +------------------------+
| Core Shard | | Precompile Shard |
| | | |
| SyscallInstrsChip | | SyscallChip(Precompile)|
| send_syscall() | | receive_syscall() |
| | | | | |
| SyscallChip(Core) | | SysLinuxChip |
| receive_syscall() | | (81 columns) |
+--------|-----------+ +---------|------------- +
| |
| global lookup message: |
| [shard, clk, |
| syscall_id, |
| arg1, arg2, |
| result_lo, result_hi] |
| |
v v
+--------------------------------------+
| GlobalChip |
| Verify send/receive multiplicities |
| Ensure result consistency |
+--------------------------------------+
Register Convention (MIPS ABI)
All registers are 32-bit (u32). In the AIR, each is represented as Word<T> = 4 x u8 (little-endian, each byte range-checked to [0, 255]).
| Register | Width | Role |
|---|---|---|
V0 | 32-bit | Syscall number (input) / return value (output) |
A0 | 32-bit | First argument |
A1 | 32-bit | Second argument |
A2 | 32-bit | Third argument (read via memory when needed) |
A3 | 32-bit | Error code output (0 = success, 9 = EBADF) |
Supported Linux Syscalls
SYS_MMAP (4210) / SYS_MMAP2 (4090) — Memory Mapping
Used by the guest allocator to request memory pages.
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | Requested address. 0 = allocate from heap. |
a1 | 32-bit | Size in bytes. Rounded up to page boundary. |
return v0 | 32-bit | Allocated address (heap pointer when a0 == 0, or a0 itself). |
output A3 | 32-bit | Always 0x00000000. |
Execution logic:
a0 == 0: returns current heap pointer, increments heap by page-aligned size.a0 != 0: returnsa0(reuse existing mapping).
Page alignment in the AIR:
The 32-bit size a1 is decomposed at the byte level to separate the 12-bit page offset from the 20-bit page-aligned upper address:
a1 = [byte0 : 8-bit] [byte1 : 8-bit] [byte2 : 8-bit] [byte3 : 8-bit]
├── lo nibble: 4-bit (boolean bit decomposition)
└── hi nibble: 4-bit (boolean bit decomposition)
page_offset = byte0 + lo_nibble * 256 (12-bit, range [0, 4095])
upper_address = hi_nibble * 4096 + byte2 * 65536 + byte3 * 16777216
The mmap_size is constrained byte-by-byte (not via field reduce()) to avoid KoalaBear prime collisions:
mmap_size[0] = 0
mmap_size[1] = hi_nibble * 16 + 16 * not_aligned - carry[0] * 256
mmap_size[2] = a1[2] + carry[0] - carry[1] * 256
mmap_size[3] = a1[3] + carry[1]
Where not_aligned = 1 when page_offset != 0 (round up to next page). The carry bits handle byte overflow from the +0x1000 addition. Page alignment (low 12 bits = 0) is structural: byte0 = 0 and every term in byte1 is a multiple of 16.
Heap update uses bytewise AddOperation (4 x u8 + 3 carry bits):
new_heap = old_heap + mmap_size.
SYS_BRK (4045) — Program Break
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | New break address. |
a1 | 32-bit | Unused. |
return v0 | 32-bit | max(a0, current_brk). |
output A3 | 32-bit | Always 0x00000000. |
AIR uses GtColsBytes (bytewise greater-than with complementary LTU lookups) to compare a0 against the BRK register.
SYS_CLONE (4120) — Process Clone (Simulated)
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | Clone flags (ignored). |
a1 | 32-bit | Child stack (ignored). |
return v0 | 32-bit | Always 0x00000001. |
output A3 | 32-bit | Always 0x00000000. |
Threading is not implemented. The syscall always returns 1 (simulated parent PID).
SYS_EXIT_GROUP (4246) — Terminate Execution
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | Exit code. |
a1 | 32-bit | Unused. |
return v0 | 32-bit | Always 0x00000000. |
output A3 | 32-bit | Always 0x00000000. |
Sets next_pc = 0 and records the exit code. Equivalent to HALT.
SYS_READ (4003) — Read from File Descriptor
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | File descriptor. Only 0 (stdin) is valid. |
a1 | 32-bit | Buffer address. |
return v0 | 32-bit | Bytes read, or 0xFFFFFFFF on error. |
output A3 | 32-bit | 0x00000000 on success, 0x00000009 (EBADF) on invalid fd. |
Only stdin (fd 0) is supported. All other fds return -1 with EBADF.
SYS_WRITE (4004) — Write to File Descriptor
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | File descriptor. |
a1 | 32-bit | Buffer address. |
A2 (implicit) | 32-bit | Byte count (read from A2 register via memory). |
return v0 | 32-bit | Bytes written (= A2 value). |
output A3 | 32-bit | Always 0x00000000. |
AIR constrains inorout.value == inorout.prev_value (read-only guard on A2 memory access).
SYS_FCNTL (4055) — File Control
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | File descriptor (0/1/2 valid). |
a1 | 32-bit | Command: 1 = F_GETFD, 3 = F_GETFL. |
return v0 | 32-bit | Flags/fd value, or 0xFFFFFFFF on error. |
output A3 | 32-bit | 0x00000000 on success, 0x00000009 on error. |
Full case matrix:
cmd (a1) | fd (a0) | result (v0) | error (A3) |
|---|---|---|---|
| 1 (F_GETFD) | 0 | 0x00000000 | 0x00000000 |
| 1 (F_GETFD) | 1 | 0x00000001 | 0x00000000 |
| 1 (F_GETFD) | 2 | 0x00000002 | 0x00000000 |
| 1 (F_GETFD) | other | 0xFFFFFFFF | 0x00000009 |
| 3 (F_GETFL) | 0 | 0x00000000 (O_RDONLY) | 0x00000000 |
| 3 (F_GETFL) | 1 | 0x00000001 (O_WRONLY) | 0x00000000 |
| 3 (F_GETFL) | 2 | 0x00000001 (O_WRONLY) | 0x00000000 |
| 3 (F_GETFL) | other | 0xFFFFFFFF | 0x00000009 |
| other | any | 0xFFFFFFFF | 0x00000009 |
AIR uses bidirectional IsZeroOperation decoders on a0 (3 decoders) and a1 (2 decoders) with exhaustive branch constraints.
NOP Syscalls — No Operation
| Arg | Width | Semantics |
|---|---|---|
a0 | 32-bit | Ignored. |
a1 | 32-bit | Ignored. |
return v0 | 32-bit | Always 0x00000000. |
output A3 | 32-bit | Always 0x00000000. |
| Syscall | Number |
|---|---|
| SYS_OPEN | 4005 |
| SYS_CLOSE | 4006 |
| SYS_MUNMAP | 4091 |
| SYS_NANOSLEEP | 4166 |
| SYS_RT_SIGACTION | 4194 |
| SYS_RT_SIGPROCMASK | 4195 |
| SYS_SIGALTSTACK | 4206 |
| SYS_FSTAT64 | 4215 |
| SYS_MADVISE | 4218 |
| SYS_GETTID | 4222 |
| SYS_SCHED_GETAFFINITY | 4240 |
| SYS_CLOCK_GETTIME | 4263 |
| SYS_OPENAT | 4288 |
| SYS_PRLIMIT64 | 4338 |
Any unrecognized Linux syscall ID also falls into the NOP path.
Cross-Shard Verification
Linux syscalls execute across two shards:
- Core shard: CPU decodes
SYSCALL, writes(shard, clk, syscall_id, arg1, arg2)toSyscallChip(Core). - Precompile shard:
SysLinuxChipcomputes the result, receives the same tuple fromSyscallChip(Precompile).
Both SyscallChip instances send two global lookup messages:
Global #1 (Syscall kind):
[shard, clk, syscall_id, arg1_lo, arg1_hi, arg2_lo, arg2_hi]
Global #2 (SyscallResult kind):
[shard, clk, syscall_id, result_lo, result_hi, 0, 0]
The GlobalChip verifies that send/receive multiplicities match for both messages. This ensures:
- Argument integrity: The Core and Precompile shards process the same 32-bit arguments (half-word packed to prevent
reduce()collisions modulo the KoalaBear prime). - Result consistency: Both shards agree on the syscall return value.
Arguments and results are packed as half-words (lo = byte0 + byte1 * 256, hi = byte2 + byte3 * 256), each U16Range-checked to [0, 65535]. This decomposition is injective for 32-bit values, unlike reduce() which can collide.
Linux vs Non-Linux Syscalls
Ziren supports two categories of syscalls, distinguished by the encoding of the syscall code in register V0:
| Property | Linux Syscalls | Non-Linux (Precompile) Syscalls |
|---|---|---|
| Syscall ID | MIPS ABI numbers (4003, 4045, 4210, ...) | Ziren-defined codes (0x00000005, 0x01010006, ...) |
| ID encoding | Byte 1 of V0 is non-zero | Byte 1 of V0 is zero |
| Proving chip | SysLinuxChip | Dedicated chip per precompile (SHA256, Poseidon2, etc.) |
| Argument handling | Full byte-level: a0/a1 as Word<T> (4 x u8) | Reduced field element: arg1 = reduce(op_b) |
| Result handling | result as Word<T>, A3 error code | Return value in V0 (precompile-specific) |
| Global linkage | Half-word packed args + result via two global lookups | Half-word packed args via one global lookup |
| Local linkage | send_syscall_result_packed with is_linux multiplicity | send_syscall / receive_syscall (reduced args only) |
How detection works
The SyscallInstrsChip examines byte 1 of the syscall code (prev_a_value[1]):
byte[1] != 0→ Linux syscall — routes toSysLinuxChipvia lookupbyte[1] == 0→ Precompile syscall — routes to the precompile's dedicated chip
This is enforced bidirectionally via an IsZeroOperation, preventing a malicious prover from misrouting a precompile call into the Linux path or vice versa.
Argument representation across the pipeline
SyscallInstrsChip (Core shard):
send_syscall(reduce(op_b), reduce(op_c)) -- reduced, for both types
send_syscall_result(op_a_word, op_b_word, op_c_word) -- byte-level, linux only
SyscallChip (bridge):
arg1 = arg1_lo + arg1_hi * 65536 -- derived inline (not stored)
arg1_lo, arg1_hi: U16Range-checked -- for ALL syscalls
Global #1: [shard, clk, id, a1_lo, a1_hi, a2_lo, a2_hi] -- collision-resistant
Global #2: [shard, clk, id, result_lo, result_hi, 0, 0] -- result linkage
SysLinuxChip (Precompile shard, linux only):
receive_syscall_result(result_word, a0_word, a1_word) -- byte-level constraints
Constrains result based on a0/a1 byte values
Other precompile chips (Precompile shard, non-linux):
receive_syscall(reduce(arg1), reduce(arg2)) -- reduced args only
Constrains output based on memory at arg addresses
The key distinction: linux syscalls need byte-level argument constraints (e.g., MMAP checks page alignment of a1 bytes, FCNTL checks a0 == 0/1/2 as integers). Non-linux precompiles typically use arguments as memory pointers and operate on the data at those addresses, so reduced field elements suffice.
AIR Soundness Properties
The SysLinuxChip enforces these key properties (all proven bidirectionally):
-
Syscall routing: Each Linux syscall ID maps to exactly one handler branch. Bidirectional
IsZeroOperationdecoders prevent misrouting (e.g., CLONE cannot be routed to NOP). -
Argument decoding:
a0 == 0/1/2anda1 == 1/3flags are bidirectional — when the argument matches a known value, the flag MUST be set. -
Result correctness: Every branch constrains both
result(V0) andoutput(A3) to specific values matching the executor semantics. -
Memory consistency: Read-only memory accesses (BRK read, A2 read) enforce
value == prev_value. Write accesses (HEAP update) use bytewiseAddOperation. -
Page alignment: MMAP size is constrained byte-by-byte. Low 12 bits of
mmap_sizeare structurally zero (byte0 = 0, byte1 is always a multiple of 16). No fieldreduce()is used. -
Cross-shard linkage: Two global lookups per syscall — one for collision-resistant argument matching (half-word packed), one for result consistency. U16Range checks on all half-words ensure canonical decomposition for both linux and non-linux syscalls.
In essence, the “computation problem” in Ziren is the given program, and its “solution” is the execution trace produced when running that program. This trace details every step of the program execution, with each row corresponding to a single step (or a cycle) and each column representing a fixed CPU variable or register state.
Proving a program essentially involves checking that every step in the trace aligns with the corresponding instruction and the expected logic of the MIPS program, convert the traces to polynomials and commit the polynomials by proof system.
Below is the workflow of Ziren.
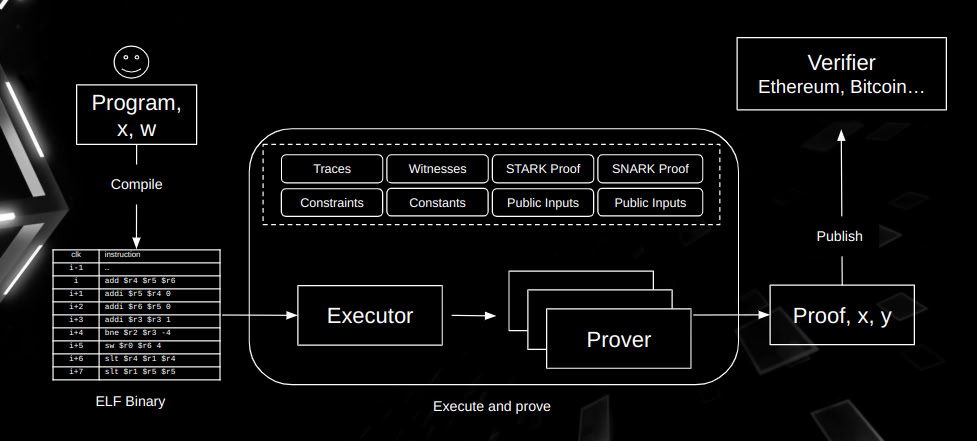
High-Level Workflow of Ziren
Referring to the above diagram, Ziren follows a structured pipeline composed of the following stages:
-
Guest Program
A program that written in a high-level language such as Rust, Go or C/C++, creating the application logic that needs to be proved. -
MIPS Compiler
The high-level program is compiled into a MIPS ELF binary using a dedicated compiler. This step compiles the program into MIPS32R2 ELF binary. -
ELF Loader
The ELF Loader reads and interprets the ELF file and prepares it for execution within the MIPS VM. This includes loading code, initializing memory, and setting up the program’s entry point. -
MIPS VM
The MIPS Virtual Machine simulates a MIPS CPU to run the loaded ELF file. It captures every step of execution—including register states, memory accesses, and instruction addresses—and generates the execution trace (i.e., a detailed record of the entire computation). -
Execution Trace
This trace is the core data structure used to verify the program. Each row represents a single step of execution, and each column corresponds to a particular CPU register or state variable. By ensuring that every step in the trace matches the intended behavior of the MIPS instructions, Ziren can prove the program was executed correctly. -
Prover
The Prover takes the execution trace from the MIPS VM and generates a zero-knowledge proof. This proof shows that the program followed the correct sequence of states without revealing any sensitive internal data. In addition, the proof is eventually used by a Verifier Contract or another verification component, often deployed on-chain, to confirm that the MIPS program executed as claimed. -
Verifier Apart from the native verifier for the generated proof, Ziren also offers a solidity verifier for EVM-compatible blockchains.
Prover Internal Proof Generation Steps
Within the Prover, Ziren employs multiple stages to efficiently process and prove the execution trace, ultimately producing a format suitable for on-chain verification:
-
Shard
To prevent memory overflow, a guest program may be split into multiple shards, allowing generation of a proof for each smaller table and then combining the proofs across tables to verify the full program execution. -
Chip
Each instruction in a shard generates one or more events (e.g., CPU and ALU events), where each event corresponds to a specific chip (CpuChip,AddSubChip, etc.) - with its own set of constraints. -
Lookup
Lookup serves two key purposes:- Cross-Chip Communication - The chip needs to send the logic which itself cannot verify to other chips for verification.
- Consistency of memory access (the data read by the memory is the data written before) - Proving that the read and write data are “permuted”.
Ziren implements these two lookup arguments through LogUp and multiset hashing hashing respectively.
-
Core Proof
The core proof includes a set of shard proofs. -
Compressed Proof
The core proof (a vector of shard proofs) is aggregated into a single compressed proof via the FRI recursive folding algorithm. -
SNARK Proof
The compressed proof is further processed using either the Plonk or Groth16 algorithm, resulting in a final Plonk proof or Groth16 proof.
In conclusion, throughout this process, Ziren seamlessly transforms a high-level program into MIPS instructions, runs those instructions to produce an execution trace, and then applies STARK, LogUp, PLONK, and Groth16 techniques to generate a succinct zero-knowledge proof. This proof can be verified on-chain to ensure both the correctness and the privacy of the computation.
Program
The setting of Ziren is that Prover runs a public program on private inputs and wants to convince Verifier that the program has executed correctly and produces an asserted output, without revealing anything about the computation’s input or intermediate state.

We consider all the inputs as private, the program and output should be public.
The program can be separated into 2 parts from a developer's perspective, the program to be proved and the program to prove.
The former program we call it guest, and the latter is host.
Host Program
In a Ziren application, the host is the machine that is running the zkVM. The host is an untrusted agent that sets up the zkVM environment and handles inputs/outputs during execution for guest.
Example: Fibonacci
This host program sends the input n = 1000 to the guest program for proving knowledge of the Nth Fibonacci number without revealing the computational path.
use zkm_sdk::{include_elf, utils, ProverClient, ZKMProofWithPublicValues, ZKMStdin}; /// The ELF we want to execute inside the zkVM. const ELF: &[u8] = include_elf!("fibonacci"); fn main() { // Create an input stream and write '1000' to it. let n = 1000u32; // The input stream that the guest will read from using `zkm_zkvm::io::read`. Note that the // types of the elements in the input stream must match the types being read in the program. let mut stdin = ZKMStdin::new(); stdin.write(&n); // Create a `ProverClient` method. let client = ProverClient::new(); // Execute the guest using the `ProverClient.execute` method, without generating a proof. let (_, report) = client.execute(ELF, stdin.clone()).run().unwrap(); println!("executed program with {} cycles", report.total_instruction_count()); // Generate the proof for the given program and input. let (pk, vk) = client.setup(ELF); let mut proof = client.prove(&pk, stdin).run().unwrap(); // Read and verify the output. // // Note that this output is read from values committed to in the program using // `zkm_zkvm::io::commit`. let n = proof.public_values.read::<u32>(); let a = proof.public_values.read::<u32>(); let b = proof.public_values.read::<u32>(); println!("n: {}", n); println!("a: {}", a); println!("b: {}", b); // Verify proof and public values client.verify(&proof, &vk).expect("verification failed"); }
For more details, please refer to document prover.
Guest Program
In Ziren, the guest program is the code that will be executed and proven by the zkVM.
Any program written in C, Go, Rust, etc. can be compiled into a MIPS32 little-endian ELF executable file using a universal MIPS compiler, that satisfies the required specification.
Ziren provides Rust runtime libraries for guest programs to handle input/output operations:
zkm_zkvm::io::read::<T>(for reading structured data)zkm_zkvm::io::commit::<T>(for committing structured data)
Note that type T must implement both serde::Serialize and serde::Deserialize. For direct byte-level operations, use the following methods to bypass serialization and reduce cycle counts:
zkm_zkvm::io::read_vec(raw byte reading)zkm_zkvm::io::commit_slice(raw byte writing)
Ziren also provides Go runtime libraries for guest programs to handle input/output operations and exit operation:
zkm_runtime.Read[T any](for reading structured data)zkm_runtime.Commit[T any](for committing structured data)zkm_runtime.RuntimeExit(for exiting program)
Guest Program Example
Ziren supports multiple programming languages. Below are examples of guest programs written in Rust and C/C++.
Rust Example: Fibonacci
//! A simple program that takes a number `n` as input, and writes the `n-1`th and `n`th Fibonacci //! number as output. // These two lines are necessary for the program to properly compile. // // Under the hood, we wrap your main function with some extra code so that it behaves properly // inside the zkVM. #![no_std] #![no_main] zkm_zkvm::entrypoint!(main); pub fn main() { // Read an input to the program. // // Behind the scenes, this compiles down to a system call which handles reading inputs // from the prover. let n = zkm_zkvm::io::read::<u32>(); // Write n to public input zkm_zkvm::io::commit(&n); // Compute the n'th fibonacci number, using normal Rust code. let mut a = 0; let mut b = 1; for _ in 0..n { let mut c = a + b; c %= 7919; // Modulus to prevent overflow. a = b; b = c; } // Write the output of the program. // // Behind the scenes, this also compiles down to a system call which handles writing // outputs to the prover. zkm_zkvm::io::commit(&a); zkm_zkvm::io::commit(&b); }
Go Example: Simple-Go
//! A simple program that takes a number `n` as input, and writes the `n`
//! number as output.
package main
import (
"log"
"github.com/ProjectZKM/Ziren/crates/go-runtime/zkm_runtime"
)
func main() {
a := zkm_runtime.Read[uint32]()
if a != 10 {
log.Fatal("%x != 10", a)
}
zkm_runtime.Commit[uint32](a)
}
C/C++ Example: Fibonacci_C
For non-Rust languages, you can compile them to static libraries and link them in Rust by FFI. For example:
extern "C" {
unsigned int add(unsigned int a, unsigned int b) {
return a + b;
}
}
unsigned int modulus(unsigned int a, unsigned int b) {
return a % b;
}
//! A simple program that takes a number `n` as input, and writes the `n-1`th and `n`th fibonacci //! number as an output. // These two lines are necessary for the program to properly compile. // // Under the hood, we wrap your main function with some extra code so that it behaves properly // inside the zkVM. #![no_std] #![no_main] zkm_zkvm::entrypoint!(main); // Use add function from Libexample.a extern "C" { fn add(a: u32, b: u32) -> u32; fn modulus(a: u32, b: u32) -> u32; } pub fn main() { // Read an input to the program. // // Behind the scenes, this compiles down to a system call which handles reading inputs // from the prover. let n = zkm_zkvm::io::read::<u32>(); // Write n to public input zkm_zkvm::io::commit(&n); // Compute the n'th fibonacci number, using normal Rust code. let mut a = 0; let mut b = 1; unsafe { for _ in 0..n { let mut c = add(a, b); c = modulus(c, 7919); // Modulus to prevent overflow. a = b; b = c; } } // Write the output of the program. // // Behind the scenes, this also compiles down to a system call which handles writing // outputs to the prover. zkm_zkvm::io::commit(&a); zkm_zkvm::io::commit(&b); }
Compiling Guest Program
Now you need compile your guest program to an ELF file that can be executed in the zkVM.
To enable automatic building of your guest crate when compiling/running the host crate, create a build.rs file in your host/ directory (adjacent to the host crate's Cargo.toml) that utilizes the zkm-build crate.
.
├── guest
└── host
├── build.rs # Add this file
├── Cargo.toml
└── src
build.rs:
fn main() { zkm_build::build_program("../guest"); }
And add zkm-build as a build dependency in host/Cargo.toml:
[build-dependencies]
zkm-build = "1.0.0"
Advanced Build Options
The build process using zkm-build can be configured by passing a BuildArgs struct to the build_program_with_args() function.
For example, you can use the default BuildArgs to batch compile guest programs in a specified directory.
use std::io::{Error, Result}; use std::io::path::PathBuf; use zkm_build::{build_program_with_args, BuildArgs}; fn main() -> Result<()> { let tests_path = [env!("CARGO_MANIFEST_DIR"), "guests"] .iter() .collect::<PathBuf>() .canonicalize()?; build_program_with_args( tests_path .to_str() .ok_or_else(|| Error::other(format!("expected {guests_path:?} to be valid UTF-8")))?, BuildArgs::default(), ); Ok(()) }
Example Walkthrough - Best Practices
From Ziren’s project template, you can directly make adjustments to the guest and host Rust programs:
- guest/main.rs
- host/main.rs
The implementations with the guest and host programs for proving the Fibonacci sequence (the default example in the project template are below):
./guest/main.rs
//! A simple program that takes a number `n` as input, and writes the `n-1`th and `n`th fibonacci //! number as an output. // These two lines are necessary for the program to properly compile. // // Under the hood, we wrap your main function with some extra code so that it behaves properly // inside the zkVM. // directives to make the Rust program compatible with the zkVM #![no_std] #![no_main] zkm_zkvm::entrypoint!(main); // marks main() as the program entrypoint when compiled for the zkVM use alloy_sol_types::SolType; // abi encoding and decoding compatible with Solidity for verification use fibonacci_lib::{PublicValuesStruct, fibonacci}; // crate with struct to represent public output values and function to compute Fibonacci numbers pub fn main() { // main function for guest. Execution begins here // Read an input to the program. // // Behind the scenes, this compiles down to a system call which handles reading inputs // from the prover. let n = zkm_zkvm::io::read::<u32>(); // reads an input n from the host. System call allows host to pass in serialized input // Compute the n'th fibonacci number using a function from the workspace lib crate. let (a, b) = fibonacci(n); // computes (n-1)th = a and nth = b Fibonacci numbers // Encode the public values of the program. let bytes = PublicValuesStruct::abi_encode(&PublicValuesStruct { n, a, b }); // wraps result into struct and ABI encodes it into a byte array using SolType // Commit to the public values of the program. The final proof will have a commitment to all the // bytes that were committed to. zkm_zkvm::io::commit_slice(&bytes); // commits output bytes to zkVM's public output allowing verifier to validate that output matches input and computation }
./host/main.rs
//! An end-to-end example of using the zkMIPS SDK to generate a proof of a program that can be executed //! or have a core proof generated. //! //! You can run this script using the following command: //! ```shell //! RUST_LOG=info cargo run --release -- --execute //! ``` //! or //! ```shell //! RUST_LOG=info cargo run --release -- --core //! ``` //! or //! ```shell //! RUST_LOG=info cargo run --release -- --compressed //! ``` use alloy_sol_types::SolType; // abi encoding and decoding compatible with Solidity for verification use clap::Parser; use fibonacci_lib::PublicValuesStruct; use zkm_sdk::{ProverClient, ZKMStdin, include_elf}; /// The ELF (executable and linkable format) file for the zkMIPS zkVM. pub const FIBONACCI_ELF: &[u8] = include_elf!("fibonacci"); // includes compiled fibonacci guest ELF binary at compile /// The arguments for the command. #[derive(Parser, Debug)] #[command(author, version, about, long_about = None)] struct Args { // defines CLI arguments #[arg(long)] execute: bool, // runs guest directly inside zkVM #[arg(long)] core: bool, // generates core proof #[arg(long)] compressed: bool, // generates compressed proof #[arg(long, default_value = "20")] n: u32, // input value to send to guest program } fn main() { // Setup the logger. zkm_sdk::utils::setup_logger(); // logging setup dotenv::dotenv().ok(); // loading any .env variables // Parse the CLI arguments and enforces exactly one mode is chosen let args = Args::parse(); if args.execute == args.core && args.compressed == args.execute { eprintln!("Error: You must specify either --execute, --core, or --compress"); std::process::exit(1); } // Setup the prover client. let client = ProverClient::new(); // Setup the inputs. let mut stdin = ZKMStdin::new(); stdin.write(&args.n); // writes n into stdin for guest to read println!("n: {}", args.n); // execution mode: if args.execute { // Execute the program let (output, report) = client.execute(FIBONACCI_ELF, stdin).run().unwrap(); println!("Program executed successfully."); // runs guest program inside zkVM without generating proof and captures output and report // Read the output. // output decoding from guest using ABI rules let decoded = PublicValuesStruct::abi_decode(output.as_slice()).unwrap(); let PublicValuesStruct { n, a, b } = decoded; // validates output correctness by re-computing it locally and comparing println!("n: {}", n); println!("a: {}", a); println!("b: {}", b); let (expected_a, expected_b) = fibonacci_lib::fibonacci(n); assert_eq!(a, expected_a); assert_eq!(b, expected_b); println!("Values are correct!"); // Record the number of cycles executed. println!("Number of cycles: {}", report.total_instruction_count()); // proving mode: } else { // Setup the program for proving. // sets up proving and verification keys from the ELF let (pk, vk) = client.setup(FIBONACCI_ELF); // Generate the Core proof let proof = if args.core { client.prove(&pk, stdin).run().expect("failed to generate Core proof") // generates compressed proof } else { client .prove(&pk, stdin) .compressed() .run() .expect("failed to generate Compressed Proof") }; println!("Successfully generated proof!"); // Verify the proof using verification key. ends process if successful client.verify(&proof, &vk).expect("failed to verify proof"); println!("Successfully verified proof!"); } }
Guest Program Best Practices
From the example above, the guest program includes the code that will be executed inside Ziren. It must be compiled to a MIPS-compatible ELF binary. Key components to include in the guest program are:
-
#![no_std],#![no_main]using the zkm_zkvm crate: this is required for the compilation to MIPS ELF#![allow(unused)] #![no_std] #![no_main] fn main() { zkm_zkvm::entrypoint!(main); } -
zkm_zkvm::entrypoint!(main): Defines the entrypoint for zkVM -
zkm_zkvm::io::read::<T>(): System call to receive input from the host -
Computation logic: Call or define functions e.g., the fibonacci function in the example (recommended to separate logic in a shared crate)
-
To minimize memory, avoid dynamic memory allocation and test on smaller inputs first to avoid exceeding cycle limits.
-
ABI encoding: Use
SolTypefromalloy_sol_typesfor Solidity-compatible public output -
zkm_zkvm::io::commit_slice: Commits data to zkVM’s public output -
For programs utilizing cryptographic operations e.g., SHA256, Keccak, BN254, Ziren provides precompiles which you can call via a syscall. For example, when utilizing the keccak precompile:
#![allow(unused)] fn main() { use zkm_zkvm::syscalls::syscall_keccak; let input: [u8; 64] = [0u8; 64]; let mut output: [u8; 32] = [0u8; 32]; syscall_keccak(&input, &mut output); }
Host Program Best Practices
The host handles setup, runs the guest, and optionally generates/verifies a proof.
The host program manages the VM execution, proof generation, and verification, handling:
- Input preparation
- zkVM execution or proof generation (core, compressed, evm-compatible)
- Output decoding
- Output validation
Structure your host around the following:
- Parse CLI args
- Load or compile guest program
- Set up for execution or proving
- Printing the verifier key
- You can define CLI args to configure the program:
#![allow(unused)] fn main() { #[derive(Parser)] struct Args { #[arg(long)] pub a: u32, #[arg(long)] pub b: u32, } }
In the above fibonacci example, execute, core, compressed and n are defined as CLI arguments:
#![allow(unused)] fn main() { #[derive(Parser, Debug)] #[command(author, version, about, long_about = None)] struct Args { // defines CLI arguments #[arg(long)] execute: bool, // runs guest directly inside zkVM #[arg(long)] core: bool, // generates core proof #[arg(long)] compressed: bool, // generates compressed proof #[arg(long, default_value = "20")] n: u32, // input value to send to guest program }
- Printing the
vkey_hashafter proof generation will bind the guest code to the verifier contract:
#![allow(unused)] fn main() { let vkey_hash = prover.vkey_hash(); println!("vkey_hash: {:?}", vkey_hash); }
Some additional best practices for output handling and validation:
- Define a
SolTypecompatible struct for outputs (e.g.,PublicValuesStruct) - Use
.abi_encode()in guest and.abi_decode()in host to ensure Solidity/verifier compatibility - Recompute expected outputs in host using
executeand assert they match guest output, ensuring correctness (expected outputs) before proving and selecting form the proving modes:-core,-compressed,-evm.
Prover
The zkm_sdk crate provides all the necessary tools for proof generation. Key features include the ProverClient, enabling you to:
- Initialize proving/verifying keys via
setup(). - Execute your program via
execute(). - Generate proofs with
prove(). - Verify proofs through
verify().
When generating Groth16 or PLONK proofs, the ProverClient automatically downloads the pre-generated proving key (pk) from a trusted setup by calling try_install_circuit_artifacts().
Example: Fibonacci
The following code is an example of using zkm_sdk in host.
use zkm_sdk::{include_elf, utils, ProverClient, ZKMProofWithPublicValues, ZKMStdin}; /// The ELF we want to execute inside the zkVM. const ELF: &[u8] = include_elf!("fibonacci"); fn main() { // Create an input stream and write '1000' to it. let n = 1000u32; // The input stream that the guest will read from using `zkm_zkvm::io::read`. Note that the // types of the elements in the input stream must match the types being read in the program. let mut stdin = ZKMStdin::new(); stdin.write(&n); // Create a `ProverClient` instance. let client = ProverClient::new(); // Execute the guest using the `ProverClient.execute` method, without generating a proof. let (_, report) = client.execute(ELF, stdin.clone()).run().unwrap(); println!("executed program with {} cycles", report.total_instruction_count()); // Generate the proof for the given program and input. let (pk, vk) = client.setup(ELF); let mut proof = client.prove(&pk, stdin).run().unwrap(); // Read and verify the output. // // Note that this output is read from values committed to in the program using // `zkm_zkvm::io::commit`. let n = proof.public_values.read::<u32>(); let a = proof.public_values.read::<u32>(); let b = proof.public_values.read::<u32>(); println!("n: {}", n); println!("a: {}", a); println!("b: {}", b); // Verify proof and public values client.verify(&proof, &vk).expect("verification failed"); }
Proof Types
Ziren provides customizable proof generation options:
#![allow(unused)] fn main() { /// A proof generated with Ziren of a particular proof mode. #[derive(Debug, Clone, Serialize, Deserialize, EnumDiscriminants, EnumTryAs)] #[strum_discriminants(derive(Default, Hash, PartialOrd, Ord))] #[strum_discriminants(name(ZKMProofKind))] pub enum ZKMProof { /// A proof generated by the core proof mode. /// /// The proof size scales linearly with the number of cycles. #[strum_discriminants(default)] Core(Vec<ShardProof<CoreSC>>), /// A proof generated by the compress proof mode. /// /// The proof size is constant, regardless of the number of cycles. Compressed(Box<ZKMReduceProof<InnerSC>>), /// A proof generated by the Plonk proof mode. Plonk(PlonkBn254Proof), /// A proof generated by the Groth16 proof mode. Groth16(Groth16Bn254Proof), } }
Core Proof (Default)
The default prover mode generates a sequence of STARK proofs whose cumulative proof size scales linearly with the execution trace length.
#![allow(unused)] fn main() { let client = ProverClient::new(); client.prove(&pk, stdin).run().unwrap(); }
Compressed Proof
The compressed proving mode generates constant-sized STARK proofs, but not suitable for on-chain verification.
#![allow(unused)] fn main() { let client = ProverClient::new(); client.prove(&pk, stdin).compressed().run().unwrap(); }
Groth16 Proof (Recommended)
The Groth16 proving mode generates succinct SNARK proofs with a compact size of approximately 260 bytes, and features on-chain verification.
#![allow(unused)] fn main() { let client = ProverClient::new(); client.prove(&pk, stdin).groth16().run().unwrap(); }
PLONK Proof
The PLONK proving mode generates succinct SNARK proofs with a compact size of approximately 868 bytes, while maintaining on-chain verifiability. In contrast to Groth16, PLONK removes the dependency on trusted setup ceremonies.
#![allow(unused)] fn main() { let client = ProverClient::new(); client.prove(&pk, stdin).plonk().run().unwrap(); }
Hardware Acceleration
GPU Acceleration
Ziren leverages CUDA-based GPU acceleration to achieve significantly lower latency and superior cost-performance relative to a CPU-based prover, even when the CPU employs AVX vector instruction extensions.
Software Requirements
To get started with the CUDA prover, please confirm that your system meets the following requirements:
Hardware Requirements
- Processor: 4-core CPU or higher
- System Memory: 16GB RAM or higher
- Graphics Card: 24GB or higher VRAM
To use Ziren with GPU acceleration, ensure your NVIDIA GPU has a compute capability of at least 8.6. You can verify this by checking the official NVIDIA documentation.
Usage
To initialize the CUDA prover, choose one of the following methods to build your client:
- Option A (Environment Variable): Use
ProverClient::new()and ensure theZKM_PROVERenvironment variable is set tocuda, eg.export ZKM_PROVER=cuda. - Option B (Direct Method): Use
ProverClient::cuda().
With the client built, you can then proceed to generate proofs using its standard methods.
CPU Acceleration
Ziren provides hardware acceleration support for AVX256/AVX512 on x86 CPUs due to support in Plonky3.
You can check your CPU's AVX compatibility by running:
grep avx /proc/cpuinfo
Check if you can see avx2 or avx512 in the results.
To activate AVX256 optimization, add these flags to your RUSTFLAGS environment variable:
RUSTFLAGS="-C target-cpu=native" cargo run --release
To activate AVX512 optimization, add these flags to your RUSTFLAGS environment variable:
RUSTFLAGS="-C target-cpu=native -C target-feature=+avx512f" cargo run --release
Network Prover
We support a network prover via the ZKM Proof Network, accessible through our RESTful API.The network prover currently supports only the Groth16 proving mode.
The proving process consists of several stages: queuing, splitting, proving, and finalizing. Each stage may take a different amount of time.
Requirements
- CA certificate:
ca.pem,ca.key. These keys are stored here - Register your address to gain access.
- SDK dependency: add
zkm_sdkfrom the Ziren SDK to yourCargo.toml:
zkm-sdk = { git = "https://github.com/ProjectZKM/Ziren" }
Environment Variable Setup
Before running your application, export the following environment variables to enable the network prover:
export ZKM_PRIVATE_KEY=<your_private_key> # Private key corresponding to your registered public key
export SSL_CERT_PATH=<path_to_ssl_certificate> # Path to the SSL client certificate (e.g., ssl.pem)
export SSL_KEY_PATH=<path_to_ssl_key> # Path to the SSL client private key (e.g., ssl.key)
You can generate the SSL certificate and key by running the certgen.sh script.
Optional: You can also set the following environment variables to customize the network prover behavior:
export SHARD_SIZE=<shard_size> # Size of each shard in bytes.
export MAX_PROVER_NUM=<max_prover_num> # Maximum number of provers to use in parallel.
export SINGLE_NODE=<true|false> # Whether to use a single node for proving (default: false).
To host your own network prover, export the following variables to configure your endpoint:
export ENDPOINT=<proof_network_endpoint> # Proof network endpoint (default: https://152.32.186.45:20002)
export CA_CERT_PATH=<path_to_ca_certificate> # Path to CA certificate (default: ca.pem)
export DOMAIN_NAME=<domain_name> # Domain name (default: "stage")
Example
The following example shows how to use the network prover on the host:
use std::env; use zkm_sdk::{include_elf, ProverClient, ZKMStdin}; const FIBONACCI_ELF: &[u8] = include_elf!("fibonacci"); fn main() { utils::setup_logger(); let mut stdin = ZKMStdin::new(); stdin.write(&10usize); let elf = test_artifacts::FIBONACCI_ELF; // create network client let client = ProverClient::network(); let (pk, vk) = client.setup(elf); let proof = client.prove(&pk, stdin).run().unwrap(); client.verify(&proof, &vk).unwrap(); }
Proof Verification Overview
Once a proof attesting to the correct execution of a computation is generated, the verifier checks whether the proof is valid. Verification requires four components:
- the verifying key: vk
- the proof itself: π
- the public inputs: x
- the result of the computation: y
For zkVMs, both the proving and verifying keys are generated from the compiled ELF binary. The proving key, together with the inputs (x), is used to generate the proof (π), which attests that the program executed correctly on the given inputs and produced the claimed output (y). Here, P(pk, x) = π.
Verification then checks that the proof, verifying key, inputs, and outputs are consistent. If the verification function V(vk, x, y, π) evaluates to true, the proof is accepted; otherwise, it is rejected.
The verifying key is produced during the key generation phase, alongside the proving key used by the prover. A 32-byte verifying key hash serves as a unique identifier, binding the proof to a specific compiled guest program and preventing it from being validated under another program’s key. Retrieve a program’s verifying key hash in code using the SDK:
#![allow(unused)] fn main() { use zkm_sdk::ProverClient; let client = ProverClient::new(); let (_pk, vk) = client.setup(ELF); let vkey_hash = vk.bytes32(); // 32-byte program verifying key hash }
On-chain verification
Ziren enables users to post and verify proofs directly on-chain. A verifier smart contract encodes the verifying key and verification logic, allowing anyone to check a proof against the declared public inputs.
When a proof and its public inputs are submitted to the verifier contract, the contract performs checks to ensure the inputs match those committed in the proof. If successful, the contract returns true; otherwise, it reverts. This approach lets applications run heavy computations off-chain, generate a succinct proof, and then verify it on-chain. Gas fees are only incurred for verification, not for executing the full computation.
Verification costs remain constant regardless of the size of the original computation. Because STARK proofs are too large to be efficiently verified on Ethereum, Ziren wraps them into Groth16 or PLONK proofs, both of which are succinct and EVM-friendly. STARK proofs are typically hundreds of kilobytes, while Groth16 proofs are only a few hundred bytes. By shrinking the proof to a more succinct format, they are more feasible to verify. Groth16 and PLONK also offer constant-time verification (O(1)) independent of circuit size, making them practical for on-chain use.
The advantage of this is rather than incurring direct gas costs for your application’s logic during execution, you can simply execute off-chain and verify your proof on-chain, paying for gas only when requesting a proof and the callback. Since verification costs remain constant regardless of the size of the original computation, whether the proof represents a small Fibonacci calculation or millions of execution steps, the gas cost depends only on the proof and the size of the public outputs (y).
Ziren currently offers the capability to post and verify a proof on testnet e.g., Sepolia. Support for on-chain verification contracts deployed on additional chains is coming soon.
Verifier Contracts in the Project Template
Ziren’s project template includes sample verifier contracts, forge scripts for deploying contracts, and Foundry tests to validate verifier functionality prior to deployment (which incurs gas costs). These include:
- IZKMVerifier — a verifier interface.
- Fibonacci.sol — an example application contract verifying a proof for a Fibonacci guest program.
- ZKMVerifierGroth16.sol and ZKMVerifierPlonk.sol — verifier instances that enforces the
VERIFIER_HASHselector, decodes inputs and calls the corresponding proof system verifier. - Groth16Verifier.sol and PLONKVerifier.sol — the contracts implementing the cryptographic verification logic of the underlying proof system.
The following is IZKMVerifier.sol, Ziren’s verifier interface:
#![allow(unused)] fn main() { // SPDX-License-Identifier: MIT pragma solidity ^0.8.20; /// @title zkMIPS Verifier Interface /// @author ZKM /// @notice This contract is the interface for the zkMIPS Verifier. interface IZKMVerifier { /// @notice Verifies a proof with given public values and vkey. /// @dev It is expected that the first 4 bytes of proofBytes must match the first 4 bytes of /// target verifier's VERIFIER_HASH. /// @param programVKey The verification key for the MIPS program. /// @param publicValues The public values encoded as bytes. /// @param proofBytes The proof of the program execution the zkMIPS zkVM encoded as bytes. function verifyProof(bytes32 programVKey, bytes calldata publicValues, bytes calldata proofBytes) external view; } interface IZKMVerifierWithHash is IZKMVerifier { /// @notice Returns the hash of the verifier. function VERIFIER_HASH() external pure returns (bytes32); } }
The verifyProof function takes the vkey, public values and proof as arguments. VERIFIER_HASH is a guardrail-type check that verifies that the first 4 bytes of the proof matches the first 4 bytes of the verifier hash. This provides a pre-check to prevent misrouted proofs and ensuring that Groth16 proofs are fed into a Groth16 verifier, PLONK proofs are fed into a PLONK verifier, etc.
The IZKMVerifier.solinterface can be used in a verifier contract. An example of its implementation can be found in the following verifier contract for the Fibonacci example:
#![allow(unused)] fn main() { // SPDX-License-Identifier: MIT pragma solidity ^0.8.20; import {IZKMVerifier} from "./IZKMVerifier.sol"; struct PublicValuesStruct { uint32 n; uint32 a; uint32 b; } /// @title Fibonacci. /// @author ZKM /// @notice This contract implements a simple example of verifying the proof of a computing a /// fibonacci number. contract Fibonacci { /// @notice The address of the zkMIPS verifier contract. /// @dev This is a specific ZKMVerifier for a specific version. IZKMVerifier public verifier; /// @notice The verification key for the fibonacci program. bytes32 public fibonacciProgramVKey; constructor(IZKMVerifier _verifier, bytes32 _fibonacciProgramVKey) { verifier = _verifier; fibonacciProgramVKey = _fibonacciProgramVKey; } /// @notice The entrypoint for verifying the proof of a fibonacci number. /// @param _proofBytes The encoded proof. /// @param _publicValues The encoded public values. function verifyFibonacciProof(bytes calldata _publicValues, bytes calldata _proofBytes) public view returns (uint32, uint32, uint32) { IZKMVerifier(verifier).verifyProof(fibonacciProgramVKey, _publicValues, _proofBytes); PublicValuesStruct memory publicValues = abi.decode(_publicValues, (PublicValuesStruct)); return (publicValues.n, publicValues.a, publicValues.b); } } }
Application contracts like **Fibonacci.sol** use the verifier interface, in addition to the verifying key, public values and proof bytes to call a deployed contract verifier such as ZKMVerifierGroth16.sol or ZKMVerifierPlonk.sol. If verification succeeds, the contract decodes and returns the public values. If it fails, the call reverts.
There are two verifier instance contracts: ZKMVerifierGroth16.sol and ZKMVerifierPlonk.sol. The following is the contract for ZKMVerifierGroth16.sol:
#![allow(unused)] fn main() { // SPDX-License-Identifier: MIT pragma solidity ^0.8.20; import {IZKMVerifier, IZKMVerifierWithHash} from "../IZKMVerifier.sol"; import {Groth16Verifier} from "./Groth16Verifier.sol"; /// @title zkMIPS Verifier /// @author ZKM /// @notice This contracts implements a solidity verifier for zkMIPS. contract ZKMVerifier is Groth16Verifier, IZKMVerifierWithHash { /// @notice Thrown when the verifier selector from this proof does not match the one in this /// verifier. This indicates that this proof was sent to the wrong verifier. /// @param received The verifier selector from the first 4 bytes of the proof. /// @param expected The verifier selector from the first 4 bytes of the VERIFIER_HASH(). error WrongVerifierSelector(bytes4 received, bytes4 expected); /// @notice Thrown when the proof is invalid. error InvalidProof(); function VERSION() external pure returns (string memory) { return "v1.0.0"; } /// @inheritdoc IZKMVerifierWithHash function VERIFIER_HASH() public pure returns (bytes32) { return 0xc7bd17e8b69c0f5d28ad39a60019df51079a6aa160013bc4a4485219a97fec97; } /// @notice Hashes the public values to a field elements inside Bn254. /// @param publicValues The public values. function hashPublicValues(bytes calldata publicValues) public pure returns (bytes32) { return sha256(publicValues) & bytes32(uint256((1 << 253) - 1)); } /// @notice Verifies a proof with given public values and vkey. /// @param programVKey The verification key for the MIPS program. /// @param publicValues The public values encoded as bytes. /// @param proofBytes The proof of the program execution the zkMIPS zkVM encoded as bytes. function verifyProof(bytes32 programVKey, bytes calldata publicValues, bytes calldata proofBytes) external view { bytes4 receivedSelector = bytes4(proofBytes[:4]); bytes4 expectedSelector = bytes4(VERIFIER_HASH()); if (receivedSelector != expectedSelector) { revert WrongVerifierSelector(receivedSelector, expectedSelector); } bytes32 publicValuesDigest = hashPublicValues(publicValues); uint256[2] memory inputs; inputs[0] = uint256(programVKey); inputs[1] = uint256(publicValuesDigest); uint256[8] memory proof = abi.decode(proofBytes[4:], (uint256[8])); this.Verify(proof, inputs); } }
This contract executes a series of checks to determine whether a proof is valid. If all checks pass, the proof is accepted. The verification process includes:
- An initial guardrail check to ensure proof type compatibility by checking that the first 4 bytes of
proofBytesmatch the contract’sVERIFIER_HASH. - Confirming that the proof is tied to the correct program verifying key (
programVKey), such as Fibonacci’s vKey. - Checking that the proof’s embedded public inputs match the declared public output bytes of the guest program.
- Delegating to the appropriate underlying proof-system verifier, either
Groth16VerifierorPlonkVerifier.
The Groth16Verifier and PlonkVerifier contracts implement the core cryptographic logic for their respective proof systems. For example, Groth16Verifier performs pairing checks over bn128 precompiles.
Deployment scripts for these verifiers are provided in the contracts > scripts directory. Specifically, ZKMVerifierGroth16.s.sol and ZKMVerifierPlonk.s.sol deploy the corresponding verifier contracts.
Below is the ZKMVerifierGroth16.s.sol script:
#![allow(unused)] fn main() { // SPDX-License-Identifier: UNLICENSED pragma solidity ^0.8.13; import {Script, console} from "forge-std/Script.sol"; import {ZKMVerifier} from "../src/v1.0.0/ZKMVerifierGroth16.sol"; contract ZKMVerifierGroth16Script is Script { ZKMVerifier public verifier; function setUp() public {} function run() public { vm.startBroadcast(); verifier = new ZKMVerifier(); vm.stopBroadcast(); } } }
The Forge script deploys the selected verifier contract ( ZKMVerifierGroth16.sol) to a target network. The script starts broadcasting, deploys the verifier, then stops broadcasting while recording the verification time. Once completed, the deployed verifier’s address is outputted.
From the end-user perspective, contracts can be deployed and bytecode published using the Forge script command. For example:
forge script scripts/ZKMVerifierGroth16.sol:ZKMVerifierGroth16 \
--rpc-url $RPC_URL --private-key $PK --broadcast
This command executes the script and deploys the ZKMVerifierGroth16 contract to the specified network.
Running this process locally (without broadcasting) simulates an EVM call against the deployed verifier contract. This is considered off-chain verification, since the verification logic executes locally and only returns the result.
When deployed, the verifier logic is placed on Ethereum at a specific contract address, making proof verification publicly accessible. The main value proposition of on-chain deployment is public verifiability: once the verifier is live, anyone can call it with programVKey, publicValues, and proofBytes.
The deployed contract points to the correct verifier implementation (e.g., ZKMVerifierGroth16), and users interact with it by calling the verifyProof() function.
The proof lifecycle for EVM-based verification is as follows:
- After proof generation, the proof bytes, verifying key, and public values are submitted in a transaction to the deployed verifier contract (e.g.,
ZKMVerifierGroth16). - Full nodes execute the verifier contract, checking that the proof matches the verifying key, that the public values are consistent, and that all cryptographic constraints of the proof system hold.
- If the proof is valid, the call succeeds and Ethereum records the result in its state. If invalid, the transaction reverts.
Although verification incurs a gas cost it runs in constant time where the cost is independent of the size of the original computation.
Off-chain verification
In addition to on-chain verification through deployed verifier contracts, Ziren offer off-chain verification for all supported proof systems.
Off-chain verification allows developers to check STARK (core and compressed), PLONK, and Groth16 proofs directly, without incurring gas. This approach also avoids the overhead of STARK-to-SNARK wrapping, since STARK proofs can also be verified natively.
Because the verification runs on a local CPU rather than on-chain, the process does not costs related to gas (unlike EVM-based verification) or dispute resolution (unlike BitVM-based verification). However, unlike on-chain verification, off-chain verification is not publicly verifiable. The result is only visible locally to the entity performing the check.
WASM Verification
Ziren provides WASM bindings for verifying Groth16, PLONK, and STARK proofs in-browser. These bindings are generated from Rust functions in the zkm_verifier crate and exposed to JavaScript via wasm_bindgen. See the ziren-wasm-verifier repository for setup instructions.
The repository includes the following:
- The guest program (with an example on computing the Fibonacci sequence) takes an input
n, commits it to the public values, computes the sequence, and writes outputs (a,b) to public values via zkVM syscalls. - The host program compiles the guest to an ELF using
zkm_build, runs setup withProverClient, generates the proof, and saves the proof, public values, and verifying key hash. - The verifier directory wraps the Rust verifier functions with
wasm_bindgenso they can be invoked from JavaScript after runningwasm-pack build.
The following is an example verifier wrapper (verifier/lib.rs):
#![allow(unused)] fn main() { //! A simple wrapper around the `zkm_verifier` crate. use wasm_bindgen::prelude::wasm_bindgen; use zkm_verifier::{ Groth16Verifier, PlonkVerifier, StarkVerifier, GROTH16_VK_BYTES, PLONK_VK_BYTES, }; /// Wrapper around [`zkm_verifier::StarkVerifier::verify`]. #[wasm_bindgen] pub fn verify_stark(proof: &[u8], public_inputs: &[u8], zkm_vk: &[u8]) -> bool { StarkVerifier::verify(proof, public_inputs, zkm_vk).is_ok() } /// Wrapper around [`zkm_verifier::Groth16Verifier::verify`]. /// /// We hardcode the Groth16 VK bytes to only verify Ziren proofs. #[wasm_bindgen] pub fn verify_groth16(proof: &[u8], public_inputs: &[u8], zkm_vk_hash: &str) -> bool { Groth16Verifier::verify(proof, public_inputs, zkm_vk_hash, *GROTH16_VK_BYTES).is_ok() } /// Wrapper around [`zkm_verifier::PlonkVerifier::verify`]. /// /// We hardcode the Plonk VK bytes to only verify Ziren proofs. #[wasm_bindgen] pub fn verify_plonk(proof: &[u8], public_inputs: &[u8], zkm_vk_hash: &str) -> bool { PlonkVerifier::verify(proof, public_inputs, zkm_vk_hash, *PLONK_VK_BYTES).is_ok() } }
All Rust functions in the zkm_verifier crate encoding the verification logic for the proof systems are wrapped to generate WASM bindings.
The repository also contains a few examples. The wasm_example script demonstrates verifying proofs in Node.js:
#![allow(unused)] fn main() { /** * This script verifies the proofs generated by the script in `example/host`. * * It loads json files in `example/json` and verifies them using the wasm bindings * in `example/verifier/pkg/zkm_wasm_verifier.js`. */ import * as wasm from "../../verifier/pkg/zkm_wasm_verifier.js" import fs from 'node:fs' import path from 'node:path' // Convert a hexadecimal string to a Uint8Array export const fromHexString = (hexString) => Uint8Array.from(hexString.match(/.{1,2}/g).map((byte) => parseInt(byte, 16))); const files = fs.readdirSync("../json"); // Iterate through each file in the data directory for (const file of files) { try { // Read and parse the JSON content of the file const fileContent = fs.readFileSync(path.join("../json", file), 'utf8'); const proof_json = JSON.parse(fileContent); // Determine the ZKP type (Groth16 or Plonk) based on the filename const file_name = file.toLowerCase(); const zkpType = file_name.includes('groth16') ? 'groth16' : file_name.includes('plonk')? 'plonk' : 'stark'; const proof = fromHexString(proof_json.proof); const public_inputs = fromHexString(proof_json.public_inputs); const vkey_hash = proof_json.vkey_hash; // Get the values using DataView. const view = new DataView(public_inputs.buffer); // Read each 32-bit (4 byte) integer as little-endian const n = view.getUint32(0, true); const a = view.getUint32(4, true); const b = view.getUint32(8, true); console.log(`n: ${n}`); console.log(`a: ${a}`); console.log(`b: ${b}`); if (zkpType == 'stark') { const vkey = fromHexString(proof_json.vkey); const startTime = performance.now(); const result = wasm.verify_stark(proof, public_inputs, vkey); const endTime = performance.now(); console.log(`${zkpType} verification took ${endTime - startTime}ms`); console.assert(result, "result:", result, "proof should be valid"); console.log(`Proof in ${file} is valid.`); } else { // Select the appropriate verification function and verification key based on ZKP type const verifyFunction = zkpType === 'groth16' ? wasm.verify_groth16 : wasm.verify_plonk; const startTime = performance.now(); const result = verifyFunction(proof, public_inputs, vkey_hash); const endTime = performance.now(); console.log(`${zkpType} verification took ${endTime - startTime}ms`); console.assert(result, "result:", result, "proof should be valid"); console.log(`Proof in ${file} is valid.`); } } catch (error) { console.error(`Error processing ${file}: ${error.message}`); } } }
The following logic is included in the script:
- Loads proof JSON files from
example/json/. - Decodes hex-encoded proof and public inputs.
- Dispatches verification to the appropriate WASM binding (
verify_stark,verify_groth16, orverify_plonk).
STARK verification requires converting the verifying key to bytes and passing it explicitly, while Groth16 and PLONK require the vkey_hash.
This example logs:
- Input values (n, a, b)
- Verification time (in ms)
- Whether the proof is valid
The eth_wasm example demonstrates in-browser STARK verification for Ethereum block proofs as part of the EthProofs initiate.
main.js:
/**
* This script verifies the proofs generated by the script in `example/host`.
*
* It loads json files in `example/json` and verifies them using the wasm bindings
* in `example/verifier/pkg/zkm_wasm_verifier.js`.
*/
import * as wasm from "../../verifier/pkg/zkm_wasm_verifier.js"
import fs from 'node:fs'
const vkey = fs.readFileSync('../binaries/eth_vk.bin');
// Download the proof from https://ethproofs.org/blocks/23174100 > ZKM
const proof = fs.readFileSync('../binaries/23174100_ZKM_167157.txt');
const startTime = performance.now();
const result = wasm.verify_stark_proof(proof, vkey);
const endTime = performance.now();
console.log(`stark verification took ${endTime - startTime}ms`);
console.assert(result, "result:", result, "proof should be valid");
console.log(`ETH proof is valid.`);
The script’s main functions are:
- Loading the verifier WASM module with Rust bindings
- Reading the verifying key
- Reading the Ethereum block proof file
- Calling the
verify_stark_prooffunction - Measuring verification time
- Checking whether the proof is valid
The script in the example/binaries directory demonstrates these steps using a STARK verifying key downloaded from the Ziren prover network and a sample proof from EthProofs, which attests that Ethereum Block 23,174,000 was executed correctly. Users can also download and run in-browser verification for Ziren directly from EthProofs. The verification process uses the WASM bindings generated by wasm-pack build, which expose the verify_stark_proof function wrapping the Rust StarkVerifier.
During execution, the script records start and end times to measure verification latency. The call wasm.verify_stark_proof(proof, vkey) runs verification in WASM by parsing the proof bytes, checking the proof against the verifying key, and confirming correctness.
Unlike the generic wasm_example, which requires passing explicit public outputs to verify_stark, the EthProofs example uses only the verify_stark_proof function. Here, all relevant public data is embedded directly within the proof. The verifier checks that the proof is valid against the verifying key and that the committed public inputs are consistent with the proof itself. This design removes the need to pass public inputs separately, reducing overhead and making block-level verification faster.
The EthProofs project uses a modified version of the WASM verifier, published as an npm package: @ethproofs/ziren-wasm-stark-verifier.
Using the fibonacci example, the expected output including the public inputs used, verification time and confirmation of the proof’s validity is as follows:
#![allow(unused)] fn main() { n: 1000 a: 5965 b: 3651 groth16 verification took 10827.951916999999ms Proof in fibonacci_groth16_proof.json is valid. n: 1000 a: 5965 b: 3651 plonk verification took 20315.557584000002ms Proof in fibonacci_plonk_proof.json is valid. n: 1000 a: 5965 b: 3651 stark verification took 30252.595458ms Proof in fibonacci_stark_proof.json is valid. }
no_std Verification
Ziren also supports verifying STARK, Groth16, and PLONK proofs in no_std environments, making it possible to run proof verification logic without depending on the Rust standard library. This allows the verifier to:
- Run in resource-constrained or bare-metal environments.
- Execute inside the zkVM as a guest program.
This approach is especially useful for off-chain computation pipelines, such as client-side verification or pre-verification before submitting proofs on-chain.
This approach is especially useful for off-chain computation pipelines, such as client-side verification or pre-verification before submitting proofs on-chain.
In the no_std model, the verifier itself is compiled as a guest binary and executed inside the zkVM. The workflow is as follows:
- Compile the verifier guest in Rust (no_std style). The guest reads inputs, runs the verifier logic, and prints success/failure.
- Provide inputs via
ZKMStdinstream from the host. These include proof bytes, public values, and the verifying key hash. - Execute inside zkVM. The host runs the verifier guest program in the zkVM.
Because all no_std targets run outside of a full OS runtime, verification is performed entirely off-chain. Additionally, recursive verification is possible: a verifier guest can itself be wrapped in a proof, producing a proof-of-verification. This enables recursive proof composition.
As an example of using no_std verification for verifying Groth16 proofs, see the groth16 example.
The following is the host program implementation for a Groth16 proof of the Fibonacci program:
//! A script that generates a Groth16 proof for the Fibonacci program, and verifies the //! Groth16 proof in ZKM. use zkm_sdk::{include_elf, utils, HashableKey, ProverClient, ZKMStdin}; /// The ELF for the Groth16 verifier program. const GROTH16_ELF: &[u8] = include_elf!("groth16-verifier"); /// The ELF for the Fibonacci program. const FIBONACCI_ELF: &[u8] = include_elf!("fibonacci"); /// Generates the proof, public values, and vkey hash for the Fibonacci program in a format that /// can be read by `zkm-verifier`. /// /// Returns the proof bytes, public values, and vkey hash. fn generate_fibonacci_proof() -> (Vec<u8>, Vec<u8>, String) { // Create an input stream and write '20' to it. let n = 20u32; // The input stream that the program will read from using `zkm_zkvm::io::read`. Note that the // types of the elements in the input stream must match the types being read in the program. let mut stdin = ZKMStdin::new(); stdin.write(&n); // Create a `ProverClient`. let client = ProverClient::new(); // Generate the groth16 proof for the Fibonacci program. let (pk, vk) = client.setup(FIBONACCI_ELF); println!("vk: {:?}", vk.bytes32()); let proof = client.prove(&pk, stdin).groth16().run().unwrap(); (proof.bytes(), proof.public_values.to_vec(), vk.bytes32()) } fn main() { // Setup logging. utils::setup_logger(); // Generate the Fibonacci proof, public values, and vkey hash. let (fibonacci_proof, fibonacci_public_values, vk) = generate_fibonacci_proof(); // Write the proof, public values, and vkey hash to the input stream. let mut stdin = ZKMStdin::new(); stdin.write_vec(fibonacci_proof); stdin.write_vec(fibonacci_public_values); stdin.write(&vk); // Create a `ProverClient`. let client = ProverClient::new(); // Execute the program using the `ProverClient.execute` method, without generating a proof. let (_, report) = client.execute(GROTH16_ELF, stdin).run().unwrap(); println!("executed groth16 program with {} cycles", report.total_instruction_count()); println!("{}", report); }
The host compiles and proves a target program (e.g., Fibonacci) to generate the proof, public values, and verifying key. These values are serialized and written to the zkVM input channel (ZKMStdin). The host then executes the verifier guest ELF inside the zkVM, reading the inputs from stdin and verifying the proof with client.prove(&pk, stdin).groth16().run().unwrap().
The following is the corresponding guest program implementation:
//! A program that verifies a Groth16 proof in ZKM. #![no_main] zkm_zkvm::entrypoint!(main); use zkm_verifier::Groth16Verifier; pub fn main() { // Read the proof, public values, and vkey hash from the input stream. let proof = zkm_zkvm::io::read_vec(); let zkm_public_values = zkm_zkvm::io::read_vec(); let zkm_vkey_hash: String = zkm_zkvm::io::read(); // Verify the groth16 proof. let groth16_vk = *zkm_verifier::GROTH16_VK_BYTES; println!("cycle-tracker-start: verify"); let result = Groth16Verifier::verify(&proof, &zkm_public_values, &zkm_vkey_hash, groth16_vk); println!("cycle-tracker-end: verify"); match result { Ok(()) => { println!("Proof is valid"); } Err(e) => { println!("Error verifying proof: {:?}", e); } } }
The guest reads all the inputs, including the proof, public values and verifying key hash from ZKMStdin provided by the host. The guest then runs Groth16Verifier::verify checking that:
- The proof is valid for the given circuit (
groth16_vk) - The committed public values match those in the proof
- The verifying key hash matches
BitVM Verifier
BitVM-based verification combines both off-chain and on-chain steps depending on the phase of the process. Ziren integrates with GOAT Network’s BitVM2 node to support verification in a Bitcoin-native environment, which allows ZK proofs to ultimately inherit Bitcoin’s security guarantees.
Ziren generates a proof for each L2 block, which is then ingested and stored by the BitVM2 node. These individual block proofs are recursively aggregated, and can be wrapped (for example into Groth16 format) to support other verification environments. BitVM2 implements an optimistic fraud-proof mechanism. In the default case, proofs are accepted based on off-chain checks and periodic sequencer commitments. If, however, an invalid proof is suspected, honest validators can trigger a challenge protocol. This protocol reduces the entire computation trace to a single disputed step, which is then resolved directly on Bitcoin L1. By doing so, the protocol ensures that verified proofs settled through BitVM2 achieve security equivalent to Bitcoin consensus while enabling efficient ZK-based verification.
Proofs are verified off-chain for peg-ins, peg-outs and sequencer commitments. During a peg-in, an SPV proof is generated proving that the user’s transaction of their deposit was included in a valid block. The GOAT contract and committee verify this proof off-chain. During a peg-out, Ziren generates a ZK proof that attests to the correctness of the PegBTC burn and the L2 state. This proof is initially checked off-chain by watchers, the committee, and potential challengers.
If no dispute is raised, the operator is reimbursed without requiring any further on-chain action. If a dispute is raised, the on-chain challenge process begins. The Watchtower generates the longest chain proof and verifies that the operator’s Kickoff commitment matches the canonical longest chain. If this chain-level check passes, challengers can proceed to the circuit-level dispute. At that stage, the entire execution trace is revealed and challenge protocol narrows the disagreement down to to the disputed computation. The Bitcoin covenant then executes the check on-chain to verify if the step belongs to the committed state and if the state transition is either valid or invalid. As a result, direct costs are only incurred during disputes.
In addition to bridging operations, the BitVM2 protocol also requires sequencer set commitments. Periodically, the committee commits the sequencer set (sequencer public keys) to Bitcoin L1. Merkle proofs of individual sequencers can then be verified off-chain against this root, ensuring that the sequencers producing L2 blocks are consistent with the commitments.
Overall, this design makes it so that proofs are not posted to Bitcoin for every block. Although proofs are generated per block, they are stored and aggregated off-chain, and verification by default also takes place off-chain. The Bitcoin L1 is only involved in periodic sequencer commitments and in disputes, where a single step is checked on-chain.
Note that in the EVM verification based setting, every proof must be submitted and verified on-chain, with each verification incurring a gas cost. Verification is also immediate and canonical in Ethereum state. By contrast, BitVM2 verification avoids per-proof L1 costs, only escalating to Bitcoin L1 in the presence of fraud dispute, while still anchoring security in Bitcoin consensus.
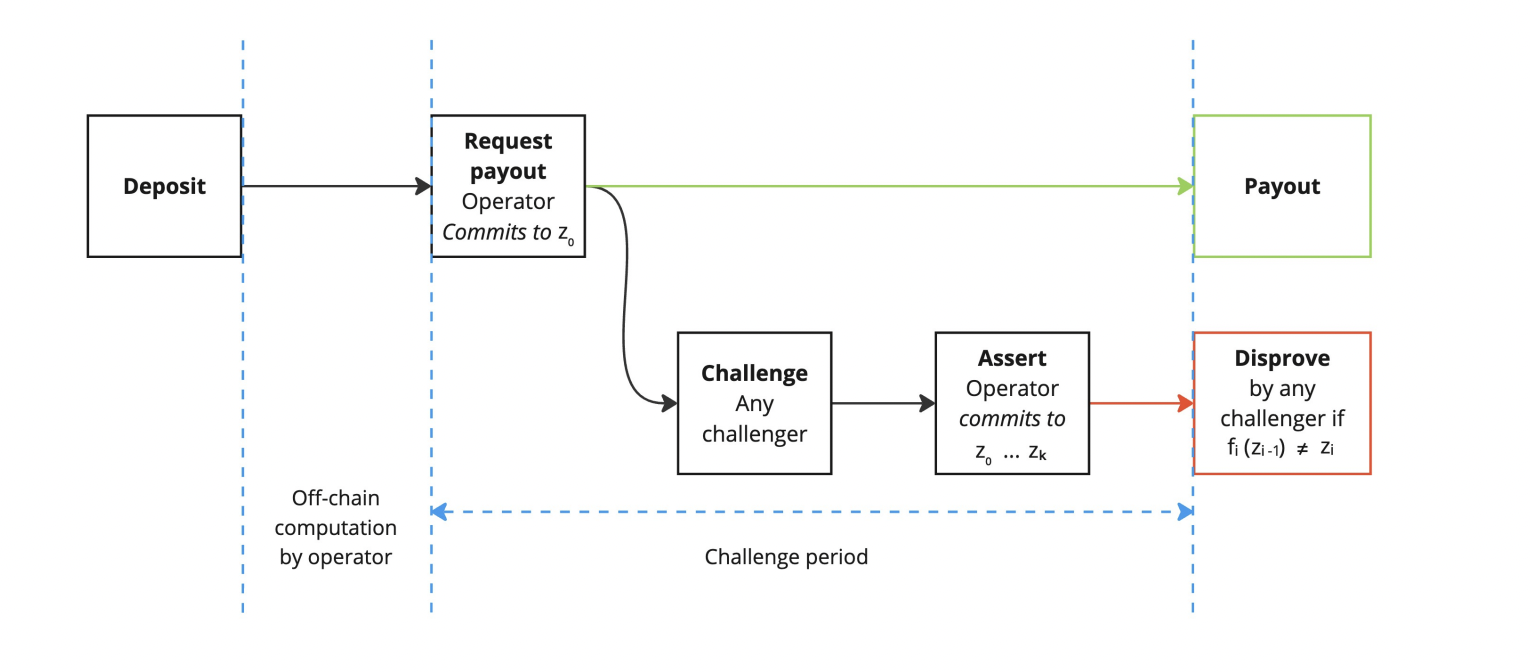
BitVM transaction flow. See the full paper here.
Proof Aggregation
With aggregation, multiple proofs can be combined together into a single aggregated proof by verifying each proof generated by Ziren inside the Ziren zkVM. A toy example of using aggregation for Fibonacci proofs can be found in Ziren’s examples directory here.
In this example, multiple proofs proving the execution of a Fibonacci sequence for different values of n are combined into a single higher-level “aggregated” proof. This higher-level proof proves that the collection of all the other Fibonacci individual proofs are valid.
Instead of verifying each proof one by one, a verifier only needs to check a single aggregated proof. The batching of many small computations into a single proof reduces verification costs and enables applications such as block aggregation, where many transactions in a block can be proven with one single succinct proof.
The host generates individual proofs, the guest recursively verifies them, and the final output aggregated proof can be cheaply verified.
The following is the guest program implementation in the example:
guest > main.rs:
//! A simple program that aggregates the proofs of multiple programs proven with the zkVM.
#![no_main]
zkm_zkvm::entrypoint!(main);
use sha2::{Digest, Sha256};
pub fn main() {
// Read the verification keys.
let vkeys = zkm_zkvm::io::read::<Vec<[u32; 8]>>();
// Read the public values.
let public_values = zkm_zkvm::io::read::<Vec<Vec<u8>>>();
// Verify the proofs.
assert_eq!(vkeys.len(), public_values.len());
for i in 0..vkeys.len() {
let vkey = &vkeys[i];
let public_values = &public_values[i];
let public_values_digest = Sha256::digest(public_values);
zkm_zkvm::lib::verify::verify_zkm_proof(vkey, &public_values_digest.into());
}
// TODO: Do something interesting with the proofs here.
//
// For example, commit to the verified proofs in a merkle tree. For now, we'll just commit to
// all the (vkey, input) pairs.
let commitment = commit_proof_pairs(&vkeys, &public_values);
zkm_zkvm::io::commit_slice(&commitment);
}
pub fn words_to_bytes_le(words: &[u32; 8]) -> [u8; 32] {
let mut bytes = [0u8; 32];
for i in 0..8 {
let word_bytes = words[i].to_le_bytes();
bytes[i * 4..(i + 1) * 4].copy_from_slice(&word_bytes);
}
bytes
}
/// Encode a list of vkeys and committed values into a single byte array. In the future this could
/// be a merkle tree or some other commitment scheme.
///
/// ( vkeys.len() || vkeys || committed_values[0].len as u32 || committed_values[0] || ... )
pub fn commit_proof_pairs(vkeys: &[[u32; 8]], committed_values: &[Vec<u8>]) -> Vec<u8> {
assert_eq!(vkeys.len(), committed_values.len());
let mut res = Vec::with_capacity(
4 + vkeys.len() * 32
+ committed_values.len() * 4
+ committed_values.iter().map(|vals| vals.len()).sum::<usize>(),
);
// Note we use big endian because abi.encodePacked in solidity does also
res.extend_from_slice(&(vkeys.len() as u32).to_be_bytes());
for vkey in vkeys.iter() {
res.extend_from_slice(&words_to_bytes_le(vkey));
}
for vals in committed_values.iter() {
res.extend_from_slice(&(vals.len() as u32).to_be_bytes());
res.extend_from_slice(vals);
}
res
}
The guest first reads a list of verification keys and public values for each individual proof, supplied by the host. For each verification key and public value pair, the program will:
- Hash the public values with SHA-256 to obtain a fixed-size digest.
- Call
zkm_zkvm::lib::verify::verify_zkm_proof(vkey, &public_values_digest.into())to recursively check the individual proof against its associated verification key and digest.
After verifying all individual proofs, the guest commits to the entire batch of verification keys and public values pairs to build a combined byte string. This commitment becomes the public output of the aggregated proof.
The following is the host program implementation in the example:
host > main.rs:
//! A simple example showing how to aggregate proofs of multiple programs with ZKM.
use zkm_sdk::{
include_elf, HashableKey, ProverClient, ZKMProof, ZKMProofWithPublicValues, ZKMStdin,
ZKMVerifyingKey,
};
/// A program that aggregates the proofs of the simple program.
const AGGREGATION_ELF: &[u8] = include_elf!("aggregation");
/// A program that just runs a simple computation.
const FIBONACCI_ELF: &[u8] = include_elf!("fibonacci");
/// An input to the aggregation program.
///
/// Consists of a proof and a verification key.
struct AggregationInput {
pub proof: ZKMProofWithPublicValues,
pub vk: ZKMVerifyingKey,
}
fn main() {
// Setup the logger.
zkm_sdk::utils::setup_logger();
// Initialize the proving client.
let client = ProverClient::new();
// Setup the proving and verifying keys.
let (aggregation_pk, _) = client.setup(AGGREGATION_ELF);
let (fibonacci_pk, fibonacci_vk) = client.setup(FIBONACCI_ELF);
// Generate the fibonacci proofs.
let proof_1 = tracing::info_span!("generate fibonacci proof n=10").in_scope(|| {
let mut stdin = ZKMStdin::new();
stdin.write(&10);
client.prove(&fibonacci_pk, stdin).compressed().run().expect("proving failed")
});
let proof_2 = tracing::info_span!("generate fibonacci proof n=20").in_scope(|| {
let mut stdin = ZKMStdin::new();
stdin.write(&20);
client.prove(&fibonacci_pk, stdin).compressed().run().expect("proving failed")
});
let proof_3 = tracing::info_span!("generate fibonacci proof n=30").in_scope(|| {
let mut stdin = ZKMStdin::new();
stdin.write(&30);
client.prove(&fibonacci_pk, stdin).compressed().run().expect("proving failed")
});
// Setup the inputs to the aggregation program.
let input_1 = AggregationInput { proof: proof_1, vk: fibonacci_vk.clone() };
let input_2 = AggregationInput { proof: proof_2, vk: fibonacci_vk.clone() };
let input_3 = AggregationInput { proof: proof_3, vk: fibonacci_vk.clone() };
let inputs = vec![input_1, input_2, input_3];
// Aggregate the proofs.
tracing::info_span!("aggregate the proofs").in_scope(|| {
let mut stdin = ZKMStdin::new();
// Write the verification keys.
let vkeys = inputs.iter().map(|input| input.vk.hash_u32()).collect::<Vec<_>>();
stdin.write::<Vec<[u32; 8]>>(&vkeys);
// Write the public values.
let public_values =
inputs.iter().map(|input| input.proof.public_values.to_vec()).collect::<Vec<_>>();
stdin.write::<Vec<Vec<u8>>>(&public_values);
// Write the proofs.
//
// Note: this data will not actually be read by the aggregation program, instead it will be
// witnessed by the prover during the recursive aggregation process inside Ziren itself.
for input in inputs {
let ZKMProof::Compressed(proof) = input.proof.proof else { panic!() };
stdin.write_proof(*proof, input.vk.vk);
}
// Generate the plonk bn254 proof.
client.prove(&aggregation_pk, stdin).plonk().run().expect("proving failed");
});
}
In the host program, during the setup, the host will compile and load two guest programs as compiled ELF binaries: the AGGREGATION_ELF (representing the aggregation guest program) and FIBONACCI_ELF, whose corresponding guest program implementation can be found here. These programs are passed to client.setup() to generate the proving and verifying keys and to client.prove() to execute inside the zkVM and generate proofs. In this example, the host generates three compressed proofs proving the correct computation of Fibonacci for inputs n=10, 20, 30.
The host then prepares inputs corresponding to each Fibonacci proof for the aggregation guest. Specifically, the host feeds the verification key hashes and raw public values as inputs and supplies the compressed proofs and full verification keys as witness data. The guest hashes the public values to a digest and calls verify_zkm_proof(vk_hash, digest) to check each proof. After all pass, the guest commits to the batch. That commitment becomes the public output of the aggregated proof.
The aggregation program is run inside the zkVM and generates a Plonk proof (representing the aggregated proof) that certifies the validity of the three individual Fibonacci proofs.
As an overview what aggregation entails in Ziren:
- Generate individual proofs.
- Collect the verification keys and public outputs of the individual proofs.
- Inside another zkVM program (the aggregation guest), recursively verify all proofs.
- Commit to the batch as a single public commitment and generate a succinct new proof proving the correct execution of all individual proofs (the aggregated proof).
For computationally heavy applications, proving logic can be divided into multiple proofs and later aggregated into a single proof. In block-level aggregation, instead of re-executing transactions individually on-chain (which can incur high gas costs), a succinct proof attesting to the validity of all transactions in a block can be generated off-chain and verified on-chain. The aggregated proof can also be in other proof formats, such as STARK or Groth16. In addition to verification via smart contract deployment, the aggregated proof can be verified off-chain using Ziren's WASM verifier.
Precompiles
Precompiles are built into the Ziren to optimize the performance of zero-knowledge proofs (ZKPs) and related cryptographic operations. The goal is to enable more efficient handling of complex cryptographic tasks that would otherwise be computationally expensive if implemented in smart contracts.
Within the zkVM, precompiles are made available as system calls executed through the syscall MIPS instruction. Each precompile is identified by a distinct system call number and provides a specific computational interface.
Specification
For advanced users, it's possible to directly interact with the precompiles through external system calls.
Here is a list of all available system calls & precompiles.
#![allow(unused)] fn main() { //! Syscalls for the Ziren zkVM. //! //! Documentation for these syscalls can be found in the zkVM entrypoint //! `zkm_zkvm::syscalls` module. pub mod bls12381; pub mod bn254; #[cfg(feature = "ecdsa")] pub mod ecdsa; pub mod ed25519; pub mod io; pub mod keccak256; pub mod poseidon2; pub mod secp256k1; pub mod secp256r1; pub mod sha3; pub mod unconstrained; pub mod utils; #[cfg(feature = "verify")] pub mod verify; extern "C" { /// Halts the program with the given exit code. pub fn syscall_halt(exit_code: u8) -> !; /// Writes the bytes in the given buffer to the given file descriptor. pub fn syscall_write(fd: u32, write_buf: *const u8, nbytes: usize); /// Reads the bytes from the given file descriptor into the given buffer. pub fn syscall_read(fd: u32, read_buf: *mut u8, nbytes: usize); /// Executes the SHA-256 extend operation on the given word array. pub fn syscall_sha256_extend(w: *mut [u32; 64]); /// Executes the SHA-256 compress operation on the given word array and a given state. pub fn syscall_sha256_compress(w: *mut [u32; 64], state: *mut [u32; 8]); /// Executes an Ed25519 curve addition on the given points. pub fn syscall_ed_add(p: *mut [u32; 16], q: *const [u32; 16]); /// Executes an Ed25519 curve decompression on the given point. pub fn syscall_ed_decompress(point: &mut [u8; 64]); /// Executes an Sepc256k1 curve addition on the given points. pub fn syscall_secp256k1_add(p: *mut [u32; 16], q: *const [u32; 16]); /// Executes an Secp256k1 curve doubling on the given point. pub fn syscall_secp256k1_double(p: *mut [u32; 16]); /// Executes an Secp256k1 curve decompression on the given point. pub fn syscall_secp256k1_decompress(point: &mut [u8; 64], is_odd: bool); /// Executes an Secp256r1 curve addition on the given points. pub fn syscall_secp256r1_add(p: *mut [u32; 16], q: *const [u32; 16]); /// Executes an Secp256r1 curve doubling on the given point. pub fn syscall_secp256r1_double(p: *mut [u32; 16]); /// Executes an Secp256r1 curve decompression on the given point. pub fn syscall_secp256r1_decompress(point: &mut [u8; 64], is_odd: bool); /// Executes a Bn254 curve addition on the given points. pub fn syscall_bn254_add(p: *mut [u32; 16], q: *const [u32; 16]); /// Executes a Bn254 curve doubling on the given point. pub fn syscall_bn254_double(p: *mut [u32; 16]); /// Executes a BLS12-381 curve addition on the given points. pub fn syscall_bls12381_add(p: *mut [u32; 24], q: *const [u32; 24]); /// Executes a BLS12-381 curve doubling on the given point. pub fn syscall_bls12381_double(p: *mut [u32; 24]); /// Executes the Keccak Sponge pub fn syscall_keccak_sponge(input: *const u32, result: *mut [u32; 17]); /// Executes the Poseidon2 permutation pub fn syscall_poseidon2_permute(state: *mut [u32; 16]); /// Executes an uint256 multiplication on the given inputs. pub fn syscall_uint256_mulmod(x: *mut [u32; 8], y: *const [u32; 8]); /// Executes a 256-bit by 2048-bit multiplication on the given inputs. pub fn syscall_u256x2048_mul( x: *const [u32; 8], y: *const [u32; 64], lo: *mut [u32; 64], hi: *mut [u32; 8], ); /// Enters unconstrained mode. pub fn syscall_enter_unconstrained() -> bool; /// Exits unconstrained mode. pub fn syscall_exit_unconstrained(); /// Defers the verification of a valid Ziren zkVM proof. pub fn syscall_verify_zkm_proof(vk_digest: &[u32; 8], pv_digest: &[u8; 32]); /// Returns the length of the next element in the hint stream. pub fn syscall_hint_len() -> usize; /// Reads the next element in the hint stream into the given buffer. pub fn syscall_hint_read(ptr: *mut u8, len: usize); /// Allocates a buffer aligned to the given alignment. pub fn sys_alloc_aligned(bytes: usize, align: usize) -> *mut u8; /// Decompresses a BLS12-381 point. pub fn syscall_bls12381_decompress(point: &mut [u8; 96], is_odd: bool); /// Computes a big integer operation with a modulus. pub fn sys_bigint( result: *mut [u32; 8], op: u32, x: *const [u32; 8], y: *const [u32; 8], modulus: *const [u32; 8], ); /// Executes a BLS12-381 field addition on the given inputs. pub fn syscall_bls12381_fp_addmod(p: *mut u32, q: *const u32); /// Executes a BLS12-381 field subtraction on the given inputs. pub fn syscall_bls12381_fp_submod(p: *mut u32, q: *const u32); /// Executes a BLS12-381 field multiplication on the given inputs. pub fn syscall_bls12381_fp_mulmod(p: *mut u32, q: *const u32); /// Executes a BLS12-381 Fp2 addition on the given inputs. pub fn syscall_bls12381_fp2_addmod(p: *mut u32, q: *const u32); /// Executes a BLS12-381 Fp2 subtraction on the given inputs. pub fn syscall_bls12381_fp2_submod(p: *mut u32, q: *const u32); /// Executes a BLS12-381 Fp2 multiplication on the given inputs. pub fn syscall_bls12381_fp2_mulmod(p: *mut u32, q: *const u32); /// Executes a BN254 field addition on the given inputs. pub fn syscall_bn254_fp_addmod(p: *mut u32, q: *const u32); /// Executes a BN254 field subtraction on the given inputs. pub fn syscall_bn254_fp_submod(p: *mut u32, q: *const u32); /// Executes a BN254 field multiplication on the given inputs. pub fn syscall_bn254_fp_mulmod(p: *mut u32, q: *const u32); /// Executes a BN254 Fp2 addition on the given inputs. pub fn syscall_bn254_fp2_addmod(p: *mut u32, q: *const u32); /// Executes a BN254 Fp2 subtraction on the given inputs. pub fn syscall_bn254_fp2_submod(p: *mut u32, q: *const u32); /// Executes a BN254 Fp2 multiplication on the given inputs. pub fn syscall_bn254_fp2_mulmod(p: *mut u32, q: *const u32); /// Reads a buffer from the input stream. pub fn read_vec_raw() -> ReadVecResult; } #[repr(C)] pub struct ReadVecResult { pub ptr: *mut u8, pub len: usize, pub capacity: usize, } }
Guest Example: syscall_sha256_extend
In the guest program, you can call the precompile syscall_sha256_extend() in the following way:
#![allow(unused)] fn main() { zkm_zkvm::syscalls::syscall_sha256_extend }
The complete code is as follows:
#![no_std] #![no_main] zkm_zkvm::entrypoint!(main); use zkm_zkvm::syscalls::syscall_sha256_extend; pub fn main() { let mut w = [1u32; 64]; syscall_sha256_extend(&mut w); syscall_sha256_extend(&mut w); syscall_sha256_extend(&mut w); println!("{:?}", w); }
Patched Crates
Patching a crate refers to replacing the implementation of a specific interface within the crate with a corresponding zkVM precompile, which can achieve significant performance improvements.
Supported Crates
| Crate Name | Repository | Versions |
|---|---|---|
| sha2 | sha2-v0-10-8 = { git = "https://github.com/ziren-patches/RustCrypto-hashes", package = "sha2", branch = "patch-sha2-0.10.8" } | 0.10.8 |
| curve25519-dalek | curve25519-dalek = { git = "https://github.com/ziren-patches/curve25519-dalek", branch = "patch-4.1.3" } | 4.1.3 |
| secp256k1 | secp256k1 = { git = "https://github.com/ziren-patches/rust-secp256k1", branch = "patch-0.29.1" } | 0.29.1 |
| substrate-bn | substrate-bn = { git = "https://github.com/ziren-patches/bn", branch = "patch-0.6.0" } | 0.6.0 |
| rsa | rsa = { git = "https://github.com/ziren-patches/RustCrypto-RSA.git", branch = "patch-rsa-0.9.6" } | 0.9.6 |
| ecdsa | ecdsa = { git = "https://github.com/ziren-patches/signatures", package = "ecdsa", branch = "patch-ecdsa-0.16.9" } | 0.16.9 |
| k256 | k256 = { git = "https://github.com/ziren-patches/elliptic-curves", branch = "patch-k256-0.13.4" } | 0.13.4 |
| p256 | p256 = { git = "https://github.com/ziren-patches/elliptic-curves", branch = "patch-p256-0.13.2" } | 0.13.2 |
Note: revm and curve25519-dalek-ng are not currently patched in this repository; references to them may apply to external projects or future work.
Using Patched Crates
There are two approaches to using patched crates:
Option 1: Directly add the patched crates as dependencies in the guest program's Cargo.toml. For example:
[dependencies]
sha2 = { git = "https://github.com/ziren-patches/RustCrypto-hashes.git", package = "sha2", branch = "patch-sha2-0.10.8" }
Option 2: Add the appropriate patch entries to your guest's Cargo.toml. For example:
[dependencies]
sha2 = "0.10.8"
[patch.crates-io]
sha2 = { git = "https://github.com/ziren-patches/RustCrypto-hashes.git", package = "sha2", branch = "patch-sha2-0.10.8" }
When patching a crate from a GitHub repository rather than crates.io, you need to explicitly declare the source repository in the patch section. For example:
[dependencies]
ed25519-dalek = { git = "https://github.com/dalek-cryptography/curve25519-dalek" }
[patch."https://github.com/dalek-cryptography/curve25519-dalek"]
ed25519-dalek = { git = "https://github.com/ziren-patches/curve25519-dalek", branch = "patch-4.1.3" }
How to Patch a Crate
First, implement the target precompile in zkVM (e.g., syscall_keccak_sponge) with full circuit logic. Given the implementation complexity, we recommend submitting an issue for requested precompiles.
Then replace the target crate's existing implementation with the zkVM precompile (e.g., syscall_keccak_sponge). For example, we have reimplemented keccak256 by syscall_keccak_sponge, and use this implementation to replace keccak256 in the core crate.
#![allow(unused)] fn main() { if #[cfg(target_os = "zkvm")] { let output = zkm_zkvm::lib::keccak256::keccak256(bytes); B256::from(output) } }
Finally, we can use the patched crate core in the reth-processor.
Optimizations
There are various ways to optimize your program, including:
- identifying places for improvement performance via cycle tracking and profiling
- acceleration for cryptographic primitives via precompiles
- hardware prover acceleration with AVX support
- other general practices e.g., avoiding copying or serializing and deserializing data when it is not necessary
Testing Your Program
It is best practice to test your program and check its outputs prior to generating proofs and save on proof generation costs and time.
To execute your program without generating a proof, run it from the host using the ProverClient::execute API instead of generating a proof:
#![allow(unused)] fn main() { let client = ProverClient::new(); let (_, report) = client.execute(ELF, stdin).run().unwrap(); println!("executed program with {} cycles", report.total_instruction_count()); }
You can also determine the public inputs with zkm_zkvm::io::commit to commit to the public values of the program.
Acceleration Options
Acceleration via Precompiles
Precompiles are specialized circuits in Ziren’s implementation used to accelerate programs utilizing certain cryptographic operations, allowing for faster program execution and less computationally expensive workload during proving.
To use a precompile, you can directly interact with them using external system calls. Ziren has a list of all available precompiles here. The precompiles section also has an example on calling a precompile and an accompanying guest program.
Alternatively, you can interact with the precompiles through patched crates. The patched crates can be added to your dependencies for performance improvements in your programs without directly using a system call. View all of Ziren’s supported crates and examples on adding patch entries here.
An example on using these crates for proving the execution of EVM blocks using Reth can be found in reth-processor. Note the patch entries of sha2, bn, k256, p256, and alloy-primitives in the guest’s Cargo.toml file.
Acceleration via Hardware
Ziren provides hardware acceleration support for proof generation via both GPU and CPU:
- CUDA-based GPU prover, selectable via the
ZKM_PROVER=cudaenvironment variable or theProverClient::cuda()constructor. - AVX2/AVX512 optimizations on x86 CPUs via Plonky3, enabled through appropriate
RUSTFLAGSsettings.
For detailed setup and examples, see the Prover documentation.
Cycle Tracking
Tracking the number of cycles for your program’s execution can be a helpful way to identify performance bottlenecks and identify specific parts of your program for improvement. A higher number of cycles in an execution will lead to longer proving times.
To print to your console the number of execution cycles occurring while executing your program,
- cycle-tracking example:
The cycle-tracking example can help measure the execution cost of guest programs in terms of MIPS instruction cycles consisting of a host and two guest program normal.rs and report.rs that reads and prints the cycle count. For example:
#![allow(unused)] fn main() { stdout: result: 5561 stdout: result: 2940 Using cycle-tracker-report saves the number of cycles to the cycle-tracker mapping in the report. Here's the number of cycles used by the setup: 3191 }
Design
As a MIPS instruction set based zkVM, Ziren is designed to generate efficient zero-knowledge proofs for complex computations (e.g., smart contract execution). Its architecture integrates a modular state machine, custom chip design, and a hybrid proof system (STARK + SNARK).
-
Modular State Machine
The state machine serves as the central control unit, simulating MIPS instruction execution through multi-chip collaboration to ensure all state transitions are verifiable in zero-knowledge. Key submodules include the Program Chip, CPU Chip, Memory Chips, ALU Chips, Global Chip and Bytes Chip. Together they enforce equivalence between MIPS program execution and Ziren VM constraints.
-
Custom Chip Design
Ziren translates MIPS execution traces into a polynomial constraint system. To efficiently encode MIPS instructions:
- Dedicated constraint circuits are implemented for each MIPS opcode to accelerate proof generation.
- Precompiled chips handle common yet computationally intensive cryptographic operations (e.g., hashing, field arithmetic) for optimal performance.
-
Hybrid Proof System
Ziren employs a three-stage proof workflow to balance modularity and efficiency:
-
Sharded STARK Proofs:
MIPS instructions are partitioned into fixed-length shards, each verified via fast STARK proofs.
-
Recursive Aggregation:
Shard proofs are compressed using a recursive STARK composition scheme.
-
SNARK Finalization:
The aggregated proof is wrapped into a Groth16-compatible SNARK for efficient on-chain verification.
-
Proof Composition
Proof composition enables developers to implement recursive proof verification, allowing cryptographic proofs to be nested within zkVM programs.
-
State Machine
The Ziren state machine is a MIPS-compatible, register-based virtual machine designed for zero-knowledge verification of general-purpose computations. It operates as a modular system of interconnected chips/tables (terms used interchangeably), each specializing in distinct computational tasks.
Core Components:
-
Program Chip
Manages program counter (PC) and instruction stream decoding while enforcing strict PC progression aligned with MIPS pipeline stages. The program table is preprocessed and constrains the program counter, instructions and selectors for the program. The CPU chip looks up its instructions in the Program chip.
-
CPU Chip
The CPU chip serves as the central processing unit for MIPS instruction execution. Each clock cycle corresponds to a table row, indexed via the pc column from the Program chip. We constrain the transition of the pc, clk and operands in this table according to the cycle’s instruction. Each MIPS instruction has three operands: a, b, and c, and the CPU table has a separate column for the value of each of these three operands. The CPU table has no constraints for the proper execution of the instruction, nor does the table itself check that operand values originate from (or write to) correct memory addresses. Ziren relies on cross-table lookups to verify these constraints.
-
ALU Chips
The ALU chips manage common field operations and bitwise operations. These chips are responsible for verifying correctness of arithmetic and bitwise operations and through cross-table lookups from the main CPU chip to make sure executing the correct instructions.
-
Flow-Control Chips
Flow control mechanisms are fundamental components in modern computer programs, enhancing program functionality and execution flexibility by providing structured control mechanisms. In the Ziren, dedicated modules — the Branch chip and Jump chip — are implemented to handle branch instructions and jump instructions respectively within the MIPS Instruction Set Architecture (ISA).
-
Memory Chips
Memory chips are responsible for the values in the a, b, and c operand columns in CPU chip come from (or write to) the right memory addresses specified in the instruction. Ziren use multiset hashing based offline memory consistency checking in the main operation of its memory argument with several memory tables.
-
Global Chip
Global chip in Ziren is responsible for processing and verifying global lookup events (such as memory accesses, system calls), ensuring compliance with predefined rules and generating cryptographic proof data.
-
Custom Chips
Several Custom chips are used to accelecate proving time in Ziren's proof system: Poseidon2 hash, STARK compression and STARK-to-SNARK adapter.
-
Precompiled Chips:
Precompiled chips are custom-designed chips for accelerating non-MIPS cryptographic operations in Ziren. They are recommended for handling common yet computationally intensive cryptographic tasks, such as SHA-256/Keccak hashing, elliptic curve operations (e.g., BN254, Secp256k1), and pairing-based cryptography.
Each chip consists of an AIR (Algebraic Intermediate Representation) to enforce functional correctness and received/sent signal vectors to connect with other chips. This modular design enables collaborative verification of MIPS instruction execution with full computational completeness, cryptographic security, and optimized proving performance featuring parallelizable constraint generation and sublinear verification complexity.
CPU
The CPU chip handles the core logic for processing MIPS instructions. Each program cycle corresponds to a table row accessed via the pc column in the preprocessed Program table. Constraints on pc transitions, clock cycles, and operand handling are enforced through column-based verification.
The CPU architecture employs a structured column-based design to manage instruction execution, branching/jump logic, memory operations, and system calls. Key components are organized into specialized modules (represented as specific columns in the CPU table) with clearly defined constraints and interactions. The CPU table uses selector columns to distinguish instruction types and perform corresponding constraint validation.
Column Classification
The CPU columns in Ziren encapsulate the core execution context of MIPS instructions within the zkVM. Key components include:
- Shard Management: Tracks execution shards for cross-shard operations like syscalls and memory access.
- Clock System: Tracks the global clock cycles.
- Program Counter: Sequential validation via pc, next_pc, and next_next_pc for instruction flow correctness.
- Instruction Decoding: Stores opcode, operands, and immediate flags.
- Memory Access: Validates read/write operations through memory corresponding columns.
- Control Flags: Identifies instruction types and operand constraints.
- Operand Validation: Enforces register/immediate selection and zero-register checks.
Constraint Categories
Ziren's CPU constraints ensure instruction integrity across four key dimensions:
-
Flow Constraints
- Program counter continuity: Consecutive real rows satisfy
local.next_pc = next.pc. - Delay-slot carry: For non-halting successor rows,
local.next_next_pc = next.next_pc, so branch/jump targets survive across the delay slot. - Sequential rows: When
is_sequential = 1, the CPU enforcesnext_next_pc = next_pc + 4. - Shard boundary safety: The last real row of a shard must be sequential or halt. Branch/jump rows cannot end a shard because shard public values export only
next_pc, notnext_next_pc. - Clock synchronization: Synchronizes timing mechanisms for system operations.
- Program counter continuity: Consecutive real rows satisfy
-
Operand Constraints
Validates operand sources (register/immediate distinction) and enforces zero-value rules under specific conditions.
-
Memory Consistency Constraints
Address validity: Verify memory address validity. Value consistency: Verify memory consistency checking.
-
Execution Context Constraints
Instruction exclusivity: Maintains instruction type exclusivity. Real-row validation: Enforces operational validity flags for non-padded execution.
These constraints are implemented through AIR polynomial identities, cross-table lookup arguments, boolean assertions, and multi-set hashing ensuring verifiable MIPS execution within Ziren's zkVM framework.
PC Boundary Rules
The CPU chip carries both next_pc and next_next_pc in each row.
next_pcis the address of the delay-slot instruction and is always the next row'spcfor real transitions.next_next_pcis the PC after the delay slot. For sequential rows it equalsnext_pc + 4; for branch and jump rows it carries the taken or fall-through post-delay-slot target.- Shard public values expose only
start_pcandnext_pc. Because of that, a branch or jump row cannot be the last real row of a shard; otherwise itsnext_next_pctarget would be lost at the boundary.
Memory
The Memory chip family manages memory operations in the MIPS execution environment through specialized column-based constraints. It covers five core subsystems: MemoryGlobal, MemoryLocal, MemoryProgram, MemoryAccess, and MemoryInstructions. Together, they enforce the correct execution of MIPS memory operations.
MemoryGlobal
Handles cross-shard memory management, initialization/finalization of global memory blocks, enforcement of address continuity, and verification of zero-register protection
Major Columns:
- Address Tracking: Monitors shard ID and 32-bit memory addresses, while enforcing sequential order.
- Value Validation: Stores 4-byte memory values with byte-level decomposition.
- Control Flags: Identify valid operations and mark terminal addresses in access sequences.
- Zero-Register Protection: Flags operations targeting protected memory regions.
Key Constraints:
- Addresses must follow strict ascending order verified via 32-bit comparator checks.
- Memory at address 0 remains immutable after initialization.
- Cross-shard finalization requires consistency with Global chip.
MemoryLocal
Maintains single-shard memory operations, tracking read/write events within a shard and preserving initial and final value consistency between consecutive shards.
Major Columns:
- Shard Identification: Tracks initial/final shard IDs for multi-shard transitions.
- Temporal Metadata: Records start/end clock cycles of memory operations.
- Value States: Preserves original and modified values for atomicity checks.
- Time Difference Limbs: Splits clock differentials for range verification.
Key Constraints:
- Final values must correspond to explicit write operations.
- Overlapping accesses require a minimum 1-clock gap between operations.
- Decomposed bytes must recompose to valid 32-bit words.
MemoryProgram
Responsible for locking executable code into immutable memory regions during proof generation, preventing runtime modification.
Major Columns:
- Address-Value Binding: Maps fixed addresses to preloaded executable code.
- Lock Flags: Enforces write protection for program memory regions.
- Multiplicity Checks: Ensures single initialization of static memory.
Key Constraints:
- Preloaded addresses cannot be modified during runtime.
- Each code shard address must be initialized exactly once.
- Access attempts to locked regions trigger validation failures.
MemoryAccess
Ensures global state synchronization, maintaining memory coherence across shards via multiset hashing.
Major Columns:
- Previous State Tracking: Stores prior shard ID and timestamp for dependency checks.
- Time Difference Analysis: Splits timestamp gaps into 16-bit and 8-bit components.
- Shard Transition Flags: Differentiate intra-shard vs. cross-shard operations.
Key Constraints:
- Cross-shard operations must reference valid prior states.
- Timestamp differences must be constrained within 24-bit range (16+8 bit decomposition).
- Intra-shard operations require sequential clock progression.
MemoryInstructions
Validates MIPS load/store operations, verifying semantics of memory-related instructions (e.g., LW, SW, LB) and alignment rules.
Major Columns:
- Instruction Type Flags: Identifies various memory operations (LW/SB/SC/etc.).
- Address Alignment: Tracks least-significant address bits for format checks.
- Sign Conversion: Manages sign-extension logic for narrow-width loads.
- Atomic Operation Bindings: Establishes linkage between load-linked (LL) to store-conditional (SC) events.
Key Constraints:
- Word operations (LW/SW) require 4-byte alignment (enforced by verifying last 2 address bits = 0).
- Signed loads (LB/LH) perform extension using most significant bit/byte.
- SC operations succeed only if memory remains unchanged since the corresponding LL.
- Address ranges are validated through bitwise decomposition checks.
ALU
The Arithmetic Logic Unit (ALU) chips comprise specialized verification circuits designed to enforce computational correctness for all arithmetic and bitwise operations. These circuits implement cross-table lookup protocols with the main CPU table, ensuring instruction-execution integrity throughout the processor pipeline.
Modular Design
The ALU employs a hierarchical verification architecture organized by MIPS instruction class:
- AddSub Chip - Validates addition/subtraction instructions (ADD, ADDI, SUB, SUBU).
- Bitwise Chip - Verifies logical operations (AND, ANDI, OR, XOR, NOR).
- CloClz Chip - Processes count-leading-ones/zeros operations (CLO/CLZ).
- DivRem Chip - Implements division/remainder operations (DIV/REM).
- Lt Chip - Enforces signed/unsigned comparisons (SLT, SLTI, SLTU).
- Mul Chip - Handles multiplication operations (MUL, MULT, MULTU).
- ShiftLeft Chip - Executes logical left shifts (SLL, SLLI).
- ShiftRight Chip - Manages logical/arithmetic right shifts (SRL, SRA).
Each chip employs domain-specific verification to ensure accurate execution of programmed instructions and LogUp-based proper alignment with CPU table constraints, thereby guaranteeing consistency between computational results and predefined operational logic.
In Section arithmetization, we analyze the AddSub Chip to demonstrate its column architecture and constraint system implementation, providing concrete insights into ALU verification mechanisms.
Flow Control
Ziren enforces MIPS32r2 control flow verification via dedicated Branch and Jump chips, ensuring precise execution of program control instructions.
Branch Chip
MIPS branch instructions execute conditional jumps through register comparisons (BEQ/BNE for equality, BGTZ/BLEZ etc. for sign checks). They calculate targets using 16-bit offsets shifted left twice (enabling ±128KB jumps) and feature a mandatory branch delay slot that always executes the next instruction—simplifying pipelining by allowing compiler-controlled optimizations.
Structure Description
Branch chip uses columns to record the following information.
- Control Flow Management
- Tracks current and future program counter states across sequential and branching execution paths (
pc, next_pc,target_pc,next_next_pc). - Implements 32-bit address validation through dedicated range-checking components(
next_pc_range_checker, target_pc_range_checker, next_next_pc_range_checker).
- Tracks current and future program counter states across sequential and branching execution paths (
- Operand Handling System
- Stores three register/immediate values following MIPS three-operand convention (
op_a_value, op_b_value, op_c_value).
- Stores three register/immediate values following MIPS three-operand convention (
- Instruction Semantics Encoding
- Embeds five mutually exclusive flags corresponding to MIPS branch opcodes (
is_beq, is_bltz, is_blez, is_bgtz, is_bgez).
- Embeds five mutually exclusive flags corresponding to MIPS branch opcodes (
- Execution State Tracking
- Maintains dual execution path indicators for taken/not-taken branch conditions(
is_branching, not_branching).
- Maintains dual execution path indicators for taken/not-taken branch conditions(
- Comparison Logic Core
- Evaluates signed integer relationships between primary operands, generating equality, greater-than, and less-than condition flags (
a_eq_b, a_gt_b, a_lt_b).
- Evaluates signed integer relationships between primary operands, generating equality, greater-than, and less-than condition flags (
Major Constraints
We use the following key constraints to validate the branch chip:
-
Program Counter Validation
next_pcis the delay-slot PC and must match the next CPU row'spc.next_next_pcis the post-delay-slot PC carried by the current row.- Taken branch case:
next_next_pc = target_pc. - Not-taken branch case:
next_next_pc = next_pc + 4. is_branchingandnot_branchingare mutually exclusive and exhaustive for real instructions.- Branch rows cannot terminate a shard, because shard public values export only
next_pcand not the post-delay-slot target innext_next_pc.
-
Instruction Validity
- Exactly one branch instruction flag must be active per row (
1 = is_beq + ... + is_bgtz). - Instruction flags are strictly boolean values (0/1).
- Opcode validity is enforced through linear combination verification.
- Exactly one branch instruction flag must be active per row (
-
Branch Condition Logic
is_branchingandnot_branchingconsistent with condition flags.
Jump Chip
MIPS jump instructions force unconditional PC changes via absolute or register-based targets.They calculate 256MB-range addresses by combining PC's upper bits with 26-bit immediates or use full 32-bit register values. All jumps enforce a mandatory delay slot executing the next instruction—enabling compiler-driven pipeline optimizations without speculative execution.
Structure Description
Jump chip uses columns to record the following information:
-
Control Flow Management
- Tracks current program counter and jump targets (
pc, next_pc, target_pc). - Implements 32-bit address validation via dedicated range checkers (
next_pc_range_checker, target_pc_range_checker, op_a_range_checker).
- Tracks current program counter and jump targets (
-
Operand System
- Stores three operands for jump address calculation (
op_a_value, op_b_value, op_c_value).
- Stores three operands for jump address calculation (
-
Instruction Semantics
- Embeds three mutually exclusive jump-type flags (
is_jump, is_jumpi, is_jumpdirect).
- Embeds three mutually exclusive jump-type flags (
Major Constraints
We use the following key constraints to validate the jump chip:
- Instruction Validity
-
Exactly one jump instruction flag must be active per row:
#![allow(unused)] fn main() { 1 = is_jump + is_jumpi + is_jumpdirect } -
Instruction flags are strictly boolean (0/1).
-
Opcode validity enforced through linear combination verification:
#![allow(unused)] fn main() { opcode = is_jump*JUMP + is_jumpi*JUMPI + is_jumpdirect*JUMPDIRECT }
-
- Return Address Handling
- Return address is saved in op_a_value:
op_a_value is saved into op_a register only when 'op_a_0 = 0'(checked in CpuChip)#![allow(unused)] fn main() { op_a_value = next_pc + 4 }
- Return address is saved in op_a_value:
- Delay-slot / target handling
next_pcis still the delay-slot PC.- The actual jump destination is carried in
next_next_pcand becomes the successor row'snext_pcafter the delay slot executes. - Jump rows cannot be the last real row of a shard for the same reason as branches: only
next_pcis exported through shard public values.
- Range Checking
- All critical values (
op_a_value, next_pc, target_pc) are range-checked, ensuring values are valid 32-bit words.
- All critical values (
- PC Transition Logic
- Target_pc calculation via ALU operation:
#![allow(unused)] fn main() { send_alu( Opcode::ADD, target_pc = next_pc + op_b_value, is_jumpdirect ) } - Direct jumps (
is_jumpdirect) use immediate operand addition.
- Target_pc calculation via ALU operation:
Other Components
Except for CPU chip, Memory chips, and ALU chips, we also have Program chip, Bytes chip, customized Poseidon2 chip, STARK Compression chip, STARK-to-SNARK chip, and Precompiled chips.
In addition to the CPU, Memory, and ALU chips, Ziren incorporates several specialized components:
- Program Chip - Manages instruction preprocessing
- Global Chip - Processes global cross-table lookups
- Bytes Chip - Handles byte operations and u16 range check
- Poseidon2 Hash Chip - Cryptographic primitive implementation
- STARK Compression/SNARK-to-SNARK Adapter - Proof system optimization
- Precompiled Chips - Accelerated cryptographic operations
Program Chip
Program chip establishes program execution constraints through preprocessed instruction verification. The CPU chip performs lookups against this verified instruction set.
Global Chip
Global chip in Ziren is responsible for processing and verifying global lookup events (such as memory accesses, system calls), ensuring compliance with predefined rules and generating zero-knowledge data commitments.
Bytes Chip
The Bytes chip is a preprocessed table that performs 8/16-bit unsigned integer range checks and byte logic/arithmetic operations.
Poseidon2 Hash Chip
Poseidon2 enhances the original Poseidon sponge function architecture with dual operational modes: maintaining sponge construction for general hashing while incorporating domain-specific compression mechanisms. Core optimizations include:
- Matrix-based linear layer substitutions replacing partial rounds.
- Configurable function width/rate parameters.
's implementation integrates specialized permutation logic with KoalaBear field arithmetic optimizations, critical for proof compression layers and STARK-to-SNARK proof system interoperability.
STARK Compression/SNARK-to-SNARK Adapter
Three proofs are used in Ziren
- Shard Proofs: Used to verify correct execution of patched MIPS instructions (i.e., shard).
- STARK Compressed Proof: Compress shard proofs into one STARK proof.
- STARK-to-SNARK Adapter: Transform final STARK proof into Groth16-compatible SNARK proof.
After emulating MIPS instructions into STARK circuits, where each circuit processes fixed-length instruction shards, and after deriving the corresponding shard STARK proofs, these proofs are first compressed into a single STARK proof. This consolidated proof is then transformed into a SNARK proof. The chips responsible for STARK compression and the STARK-to-SNARK adapter are custom-designed specifically for proof verification over the KoalaBear field.
Precompiled Chips
Another category of chips extensively utilized in Ziren is Precompiled chips. These chips are specifically designed to handle widely used but computationally intensive cryptographic operations, such as hash functions and signature schemes.
Unlike the approach of emulating MIPS instructions, Ziren delegates these computations to dedicated precompiled tables. The CPU table then performs lookups to retrieve the appropriate values from these tables (precompiled operations are activated via syscalls). Precompiles have the capability to directly read from and write to memory through the memory argument. They are typically provided with a clock (clk) value and pointers to memory addresses, which specify the locations for reading or writing data during the operation. For a comprehensive list of precompiled tables, refer to this section.
Arithmetization
Algebraic Intermediate Representation (AIR) serves as the arithmetization foundation in the Ziren system, bridging computation and succinct cryptographic proofs. AIR provides a structured method to represent computations through polynomial constraints over execution traces.
Key Concepts of AIR
-
Execution Trace
A tabular structure where each row represents system's state at a computation step, with columns corresponding to registers/variables.
-
Transition Constraints
Algebraic relationships enforced between consecutive rows, expressed as low-degree polynomials (e.g., \(P(state_i, state_{i+1}) = 0\)).
-
Boundary Constraints
Ensure valid initial/final states (e.g., \(state_0 = initial\_value\)).
These constraints utilize low-degree polynomials for efficient proof generation/verification. Ziren mandates degree-3 polynomial constraints within its AIR framework, establishing a formally verifiable equilibrium between proof generation efficiency and trace column representation compactness. See AIR paper for rigorous technical details.
AIR Implementation in Ziren Chips
Having introduced various chip/table structures in Ziren, we note that building a chip involves:
- Matrix Population - Filling values into a matrix structure.
- Constraint Construction - Establishing relationships between values, particularly across consecutive rows.
This process aligns with AIR's core functionality by:
- Treating column values as polynomial evaluations.
- Encoding value constraints as polynomial relationships.
AddSub Chip Example
Supported MIPS Instructions
| instruction | Op [31:26] | rs [25:21] | rt [20:16] | rd [15:11] | shamt [10:6] | func [5:0] | function |
|---|---|---|---|---|---|---|---|
| ADD | 000000 | rs | rt | rd | 00000 | 100000 | rd = rs+rt |
| ADDI | 001000 | rs | rt | imm | imm | imm | rt = rs + sext(imm) |
| ADDIU | 001001 | rs | rt | imm | imm | imm | rt = rs + sext(imm) |
| ADDU | 000000 | rs | rt | rd | 00000 | 100001 | rd = rs+rt |
| SUB | 000000 | rs | rt | rd | 00000 | 100010 | rd = rs - rt |
| SUBU | 000000 | rs | rt | rd | 00000 | 100011 | rd = rs - rt |
Column Structure
#![allow(unused)] fn main() { pub struct AddSubCols<T> { // Program flow pub pc: T, pub next_pc: T, // Core operation pub add_operation: AddOperation<T>, // Shared adder for both ops (a = b + c) // Input operands (context-sensitive): // - ADD: operand_1 = b, operand_2 = c // - SUB: operand_1 = a, operand_2 = c pub operand_1: Word<T>, pub operand_2: Word<T>, // Validation flags pub op_a_not_0: T, // Non-zero guard for first operand pub is_add: T, // ADD opcode flag pub is_sub: T, // SUB opcode flag } pub struct AddOperation<T> { pub value: Word<T>, pub carry: [T; 3], } // 32-bit word structure pub struct Word<T>(pub [T; WORD_SIZE]); // WORD_SIZE = 4 }
The AddSub Chip implementation utilizes 20 columns:
operand_1.[0-3], operand_2.[0-3]: 4-byte operands (8 columns),add_operation.value.[0-3]: 4-byte results (4 columns),add_operation.carry.[0-2]: Carry flags (3 columns),pc, next_pc, op_a_not_0, is_add, is_sub: Control signals (5 columns).
Computational Validity Constraints
The corresponding constraints support (we use op_1, op_2, add_op for short of operand_1, operand_2 and add_operation respectively):
-
Zero Constraints
Enforces add/sub validity for each byte, e.g., for addition \(op\_1.0 + op\_2.0 - add\_op.value.0 = 0 \) or \(op\_1.0 + op\_2.0 - add\_op.value.0 = 256 \).
-
bool constraints
carry values are bool, e.g., \( add\_op.carry.0 \in \{0,1\} \).
-
range check 8-bits values for op_1.i, op_2.i, add_op.value.i. e.g., \(op\_1.0 \in \{0,1,2,\cdots,255\}\).
Matrix Population
Sample register state evolution:
| program count | instruction | description | .... | r1 | r2 | r3 | r4 | r5 | r6 | r7 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | initial | ...... | x | 30 | 10 | 9 | 13 | 13685 | 21 | |
| 1 | add $r5 $r6 $r7 | r7 = r5 + r6 | ...... | x | 30 | 10 | 9 | 13 | 13685 | 13698 |
| 2 | addi $r6 $r5 0 | r5 = r6 + 0 | ...... | x | 30 | 10 | 9 | 13685 | 13685 | 13698 |
| 3 | addi $r7 $r6 0 | r6 = r7 + 0 | ...... | x | 30 | 10 | 9 | 13685 | 13698 | 13698 |
| 4 | addi $r4 $r4 1 | r4 = r4 + 1 | ...... | x | 30 | 10 | 10 | 13685 | 13698 | 13698 |
| 5 | slt $r2 $r6 $r7 | r2 = r6 < r7? 1:0 | ...... | x | 0 | 10 | 10 | 13685 | 13698 | 13698 |
| 6 | sub $r6 $r4 $r5 | r5 = r6 - r4 | ...... | x | 0 | 10 | 10 | 13688 | 13698 | 13698 |
Instructions 1, 2, 3, 4, and 6 are integrated with the AddSub Chip. The trace matrix (illustrated below, with the final row highlighting polynomial constraints) delineates their computational pathways.
| pc | next_pc | add_op.value.0 | add_op.value.1 | add_op.value.2 | add_op.value.3 | add_op.carry.0 | add_op.carry.1 | add_op.carry.2 | op_1.0 | op_1.1 | op_1.2 | op_1.3 | op_2.0 | op_2.1 | op_2.2 | op_1.3 | op_a_not_0 | is_add | is_sub |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 130 | 53 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 0 | 0 | 117 | 53 | 0 | 0 | 1 | 1 | 0 |
| 2 | 3 | 119 | 53 | 0 | 0 | 0 | 0 | 0 | 119 | 53 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 3 | 4 | 130 | 53 | 0 | 0 | 0 | 0 | 0 | 130 | 53 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 4 | 5 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 6 | 7 | 120 | 53 | 0 | 0 | 0 | 0 | 0 | 130 | 53 | 0 | 0 | 10 | 0 | 0 | 0 | 1 | 0 | 1 |
| a(x) | b(x) | c(x) | d(x) | e(x) | f(x) | g(x) | h(x) | i(x) | j(x) | k(x) | l(x) | m(x) | n(x) | o(x) | p(x) | q(x) | r(x) | s(x) | t(x) |
AIR Transformation Example
Each column is represented as a polynomial defined over a 2-adic subgroup within the KoalaBear prime field. To demonstrate AIR expression, we analyze the first-byte computation in the addition operation:
\[P_{add}(x) := (j(x) + n(x) - c(x))(j(x) + n(x) - c(x)-256) = 0.\]
And for sub operation, \[P_{sub}(x) := (j(x) + n(x) - c(x))(j(x) + n(x) - c(x)-256) = 0.\]
Using operation selectors \(s(x), t(x)\), the derived polynomila constraint is \[ s(x)\cdot P_{add}(x) + t(x) \cdot P_{sub}(x) = 0.\]
Where:
- s(x): Add operation selector,
- t(x): Sub operation selector,
- j(x): First byte of op_1,
- n(x): First byte of op_2,
- c(x): First byte of result value add_op.value.
Preprocessed AIR
For invariant components (e.g., Program/Bytes chips), Ziren precomputes commitments to invariant data columns and predefines fixed AIR constraints among them during setup to establish the Preprocessed AIR framework. By removing redundant recomputation of preprocessed AIR constraints in proofs, PAIR reduces ZKP proving time.
Conclusion
The AIR framework transforms trace constraints into polynomial identities, where increased rows only expand the evaluation domain rather than polynomial complexity. Ziren also enhances efficiency through:
- Lookup Tables for range checks.
- Multiset Hashing for memory consistency.
- FRI for polynomial interactive oracle proofs (IOP).
These components constitute the foundational architecture of Ziren and will be elaborated in subsequent sections.
Lookup Arguments
Lookup arguments allow generating cryptographic proofs showing that elements from a witness vector belong to a predefined table (public or private). Given:
- Table \(T = \{t_i\}\), where \(i=0,…,N−1 \) (public/private)
- Lookups \(F = \{f_j\}\), where \(j=0,…,M−1 \) (private witness)
The protocol proves \(F \subseteq T \), ensuring all witness values adhere to permissible table entries.
Since its inception, lookup protocols have evolved through continuous optimizations. Ziren implements the LogUp protocol to enable efficient proof generation.
LogUp
LogUp employs logarithmic derivatives for linear-complexity verification. For a randomly chosen challenge \(\alpha\), the relation \(F \subseteq T\) holds with high probability when: \[ \sum_{i=0}^{M-1} \frac{1}{f_i - \alpha} = \sum_{i=0}^{N-1} \frac{m_i}{t_i - \alpha} \] , where \(m_i\) denotes the multiplicity of \(t_i\) in \(F\). See full protocol details.
LogUp Implementation in Ziren
Cross-chip verification in Ziren utilizes LogUp for consistency checks, as shown in the dependency diagram:
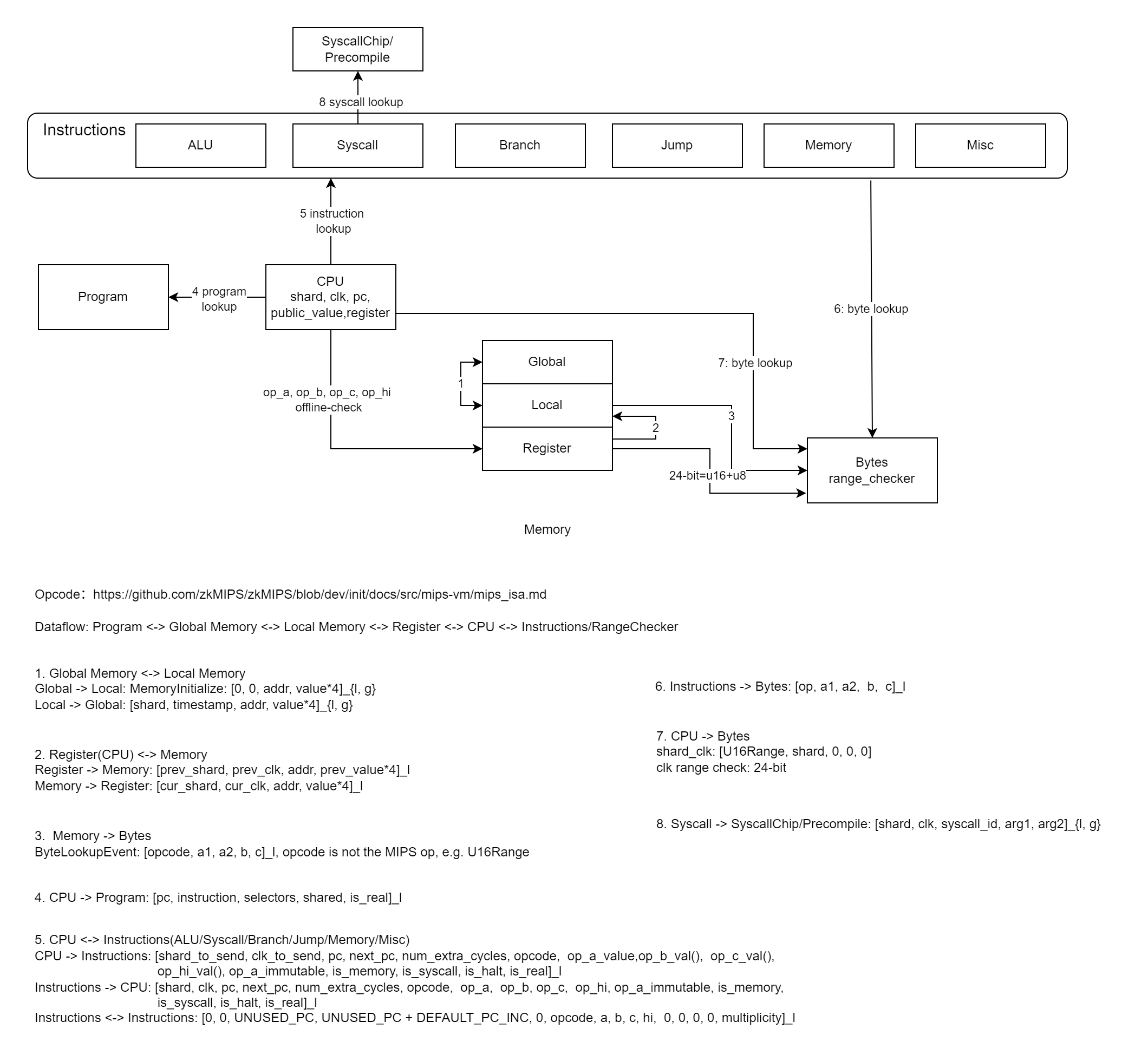
Key Lookup Relationships:
| Index | Source(F) | Target(T) | Verification Purpose |
|---|---|---|---|
| 1 | Global Memory | Local Memory | Overall memory consistency * |
| 2 | CPU | Memory | Memory access patterns |
| 3 | Memory | Bytes | 8-bit range constraints |
| 4 | CPU | Program | Instruction validity |
| 5 | CPU | Instructions | Instructions operations |
| 6 | Instructions | Bytes | Operand bytes verification |
| 7 | CPU | Bytes | Operand range verification |
| 8 | Syscall | Precompiles | Syscall/precompiled function execution |
* In the latest implementation, Ziren employs multiset-hashing to ensure memory consistency checking, enhancing proof efficiency and modularity.
Range Check Implementation Example
8-bit Range Check Design
In Ziren's architecture, 32-bit values undergo byte-wise decomposition into four 8-bit components, with each byte occupying a dedicated memory column. This structural approach enables native support for 8-bit range constraints (0 ≤ value < 255) during critical operations including arithmetic logic unit (ALU) computations and memory address verification.
- Starting Lookup Table (T)
| t |
|---|
| 0 |
| 1 |
| ... |
| 255 |
For lookups \(\{f_0, f_1, \dots, f_{M-1}\}\) (all elements in [0, 255]), we:
- Choose random \(\alpha\);
- Construct two verification tables.
-
Lookups (F)
f \(d = 1/(f-\alpha)\) sum \(f_0\) \(d_0=1/(f_0-\alpha)\) \(d_0\) \(f_1\) \(d_1=1/(f_1-\alpha)\) \(d_0 + d_1\) \(f_2\) \(d_2=1/(f_2-\alpha)\) \(d_0+d_1+d_2\) ... ... ... \(f_{M-1}\) \(d_m=1/(f_{M-1}-\alpha)\) \(\sum_{i=0}^{M-1}d_i\) -
Updated Lookup Table
t m \(d = m/(f+\alpha)\) sum 0 \(m_0\) \(d_0 = m_0/\alpha \) \(d_0\) 1 \(m_1\) \(d_1 = m_1/(1-\alpha)\) \(d_0 + d_1\) 2 \(m_2\) \(d_2 = m_2/(2-\alpha)\) \(d_0+d_1+d_2\) ... ... ... .. 255 \(m_{255}\) \(d_{255} = m_{255}/(255-\alpha)\) \(\sum_{i=0}^{255}d_i\)
,where \(m_i\) denotes the occurrence count of \(i\) in lookups.
LogUp ensures that if the final cumulative sums in both tables match (which is exactly \[ \sum_{i=0}^{M-1} \frac{1}{f_i - \alpha} = \sum_{i=0}^{N-1} \frac{m_i}{t_i - \alpha} \] ), then with high probability every \(f_i\) originates from table \(T\) (i.e., falls within 0-255 range).
Memory Consistency Checking
Offline memory checking is a method that enables a prover to demonstrate to a verifier that a read/write memory was used correctly. In such a memory system, a value \(v\) can be written to an address \(a\) and subsequently retrieved. This technique allows the verifier to efficiently confirm that the prover adhered to the memory's rules (i.e., that the value returned by any read operation is indeed the most recent value that was written to that memory address).
This is in contrast to "online memory checking" techniques like Merkle hashing which immediately verify that a memory read was done correctly by insisting that each read includes an authentication path. Merkle hashing is computationally expensive on a per-read basis for ZK provers, and offline memory checking suffices for zkVM design.
Ziren replaces ZKM’s online memory checking with multiset-hashing-based offline memory checking for improved efficiency. Ziren's verifies the consistency of read/write operations by constructing a read set \(RS\) and a write set \(WS\) and proving their equivalence. This mechanism leverages multiset hashing on an elliptic curve over KoalaBear Prime's 7th extension field to ensure memory integrity efficiently. Below is a detailed breakdown of its key components.
Construction of Read Set and Write Set
Definition: The read set \(RS\) and write set \(WS\) are sets of tuples \(a, v, c\), where:
- \(a\): Memory address
- \(v\): Value stored at address \(a\)
- \(c\): Operation counter
Three-Stage Construction
Initialization:
- \(RS = WS = \emptyset\);
- All memory cells \(a_i\) are initialized with some value \(v_i\) at op count \(c=0\). Add the initial tuples to the write set \(WS = WS \bigcup \{(a_i, v_i, 0)\}\) for all \(i\).
Read and write operations:
- Read Operation, for reading a value from address \(a\):
- Find the last tuple \((a, v, c)\) added to write set \(WS\) with the address \(a\).
- \(RS = RS \bigcup \{(a, v, c)\}\) and \(WS = WS \bigcup \{(a, v, c_{now})\}\), with \(c_{now}\) the current op count.
- Write Operation, for writing a value \(v'\) to address \(a\):
- Find the last tuple \((a, v, c)\) added to write set \(WR\) with the address \(a\).
- \(RS = RS \bigcup \{(a, v, c)\}\) and \(WS = WS \bigcup \{(a, v', c_{now})\}\).
Post-processing:
- For all memory cells \(a_i\), add the last tuple \((a_i, v_i, c_i)\) in write set \(WS\) to \(RS\): \(RS = RS \bigcup \{(a_i, v_i, c_i)\}\).
Core Observation
The prover adheres to the memory rules if the following conditions hold:
- The read and write sets are correctly initialized;
- For each address \(a_i\), the instruction count added to \(WS\) strictly increases over time;
- For read operations: Tuples added to \(RS\) and \(WS\) must have the same value.
- For write operations: The operation counter of the tuple in \(RS\) must be less than that in \(WS\).
- After post-processing, \(RS = WS\).
Brief Proof: Consider the first erroneous read memory operation. Assume that a read operation was expected to return the tuple \((a,v,c)\), but it actually returned an incorrect tuple \((a, v' \neq v, c')\) and added it to read set \(RS\). Note that all tuples in \(WS\) are distinct. After adding \((a,v',c_{now})\) to \(WS\), the tuples \((a,v,c)\) and \((a,v',c_{now})\) are not in the read set \(RS\). According to restriction 3, after each read-write operation, there are always at least two tuples in \(WS\) that are not in \(RS\), making it impossible to adjust to \(RS = WS\) through post-processing.
Multiset Hashing
Multiset hashing maps a (multi-)set to a short string, making it computationally infeasible to find two distinct sets with the same hash. The hash is computed incrementally, with order-independence as a key property.
Implementation on Elliptic Curve
Let \(G\) denote the group of points \((x,y)\) on the elliptic curve defined by \(y^2 = x^3 +Ax+B\), including the point at infinity. We adopt a hash-to-group approach following the framework described in Constraint-Friendly Map-to-Elliptic-Curve-Group Relations and Their Applications. To map a set element to a point on the curve, we first assign it directly to the \(x\)-coordinate of a candidate point—without an intermediate hashing step. Since this \(x\)-value may not correspond to a valid point on the curve, we apply an 8-bit tweak \(t\) to adjust it. The sign of the resulting \(y\)-coordinate is constrained to prevent ambiguity, either by restricting \(y\) to be a quadratic residue or by imposing explicit range checks. Furthermore, the message length is bounded by 110 bits, and the base field of the curve operates over the 7th extension field of the KolearBear Prime to ensure a security level of at least 100 bits.
In Ziren, the following parameters are used.
- KoalaBear Prime field: \(\mathbb{F}_P\), with \(P = 2^{31} - 2^{24} +1\).
- Septic extension field: Defined under irreducible polynomial \( u^7 + 2u -8\).
- Elliptic curve: Defined with \(A = 3*u , B= -3\) (provides ≥102-bit security).
Elliptic Curve Selection over KoalaBear Prime Extension Field
Objective
Construct an elliptic curve over the 7th-degree extension field of KoalaBear Prime \(P = 2^{31} - 2^{24} +1\), achieving >100-bit security against known attacks while maintaining computational efficiency.
Code Location
Implementation available here. It is a fork from Cheetah that finds secure curve over a sextic extension of Goldilock Prime \(2^{64} - 2^{32} + 1\).
Construction Workflow
-
Step 1: Sparse Irreducible Polynomial Selection
- Requirements:
- Minimal non-zero coefficients in polynomial
- Small absolute values of non-zero coefficients
- Irreducibility over base field
- Implementation (septic_search.sage):
poly = find_sparse_irreducible_poly(Fpx, extension_degree, use_root=True)- The selected polynomial: \(x^7 + 2x - 8\). This sparse form minimizes arithmetic complexity while ensuring irreducibility.
- Requirements:
-
Step 2: Candidate Curve Filtering
- Curve Form: \(y^2 = x^3 + ax + b\), with small |a| and |b| to optimize arithmetic operations.
- Parameter Search in septic_search.sage:
for i in range(wid, 1000000000, processes): coeff_a = 3 * a # Fixed coefficient scaling coeff_b = i - 3 E = EllipticCurve(extension, [coeff_a, coeff_b]) - Final parameters chosen: \(a = 3u, b = -3\) (with \(u\) as extension field generator).
-
Step 3: Security Validation
-
Pollard-Rho Resistance
Verify prime subgroup order > 210 bits:
prime_order = list(ecm.factor(n))[-1] assert prime_order.nbits() > 210 -
Embedding Degree Check:
embedding_degree = calculate_embedding_degree(E) assert embedding_degree.nbits() > EMBEDDING_DEGREE_SECURITY -
Twist Security:
- Pollard-Rho Resistance
- Embedding Degree Check
-
-
Step 4: Complex Discriminant Verification
Check discriminant condition for secure parameterization: \( D=(P^7 + 1 − n)^ 2 - 4P^7 \), where \(n\) is the full order of the original curve. Where \(\text{D}\) must satisfies:
- Large negative integer (absolute value > 100 bits)
- Square-free part > 100 bits
Validation command:
sage verify.sage
The selected curve achieves >100-bit security. This construction follows NIST-recommended practices while optimizing for zkSNARK arithmetic circuits through sparse polynomial selection and small curve coefficients.
STARK Protocol
Polynomial Constraint System Architecture
Following arithmetization, the computation is represented through a structured polynomial system.
Core Components
-
Execution Trace Polynomials
Encode state transitions across computation steps as: \[ T_i(x) = \sum_{k=0}^{N-1} t_{i,k} \cdot L_k(x),\] where \(L_k(x)\) are Lagrange basis polynomials over domain H.
-
Constraint Polynomials Encode verification conditions as algebraic relations: \[C_j(x) = R_j(T_1(x),T_2(x), \cdots, T_m(x), T_1(g \cdot x), T_2(g \cdot x), \cdots, T_m(g \cdot x)) = 0,\] for all \(x \in H\), where \(g\) is the generator of H.
Constraint Aggregation
For proof efficiency, we combine constraints using: \[C_{comb}(x) = \sum_j \alpha_j C_j(x),\] where \( \alpha_j\) are derived through the Fiat-Shamir transformation.
Mixed Matrix Commitment Scheme (MMCS)
Polynomial Commitments in STARK
STARK uses Merkle trees for polynomial commitments:
-
Setup: No trusted setup is needed, but a hash function for Merkle tree construction must be predefined. We use Poseidon2 as the predefined hash function.
-
Commit: Evaluate polynomials at all roots of unity in its domain, construct a Merkle tree with these values as leaves, and publish the root as the commitment.
-
Open: The verifier selects a random challenge point, and the prover provides the value and Merkle path for verification.
Batch Commitment Protocol
The "Mixed Matrix Commitment Scheme" (MMCS) is a generalization of a vector commitment scheme used in Ziren. It supports:
- Committing to matrices.
- Opening rows.
- Batch operations - committing to multiple matrices simultaneously, even when they differ in dimensions.
When opening a particular row index:
- For matrices with maximum height: use the full row index.
- For smaller matrices: truncate least-significant bits of the index.
These semantics are particularly useful in the FRI protocol.
Low-Degree Extension (LDE)
Suppose the trace polynomials are initially of length \(N\). For security, we evaluate them on a larger domain (e.g., \(2^k \cdot N\)), called the LDE domain.
Using Lagrange interpolation:
- Compute polynomial coefficients.
- Extend evaluations to the larger domain,
Ziren implements this via Radix2DitParallel - a parallel FFT algorithm that divides butterfly network layers into two halves.
Low-Degree Enforcement
Quotient Polynomial Construction
To prove \(C_{comb}(x)\) vanishes over subset \(H\), construct quotient polynomial \(Q(x)\): \[Q(x) = \frac{C_{comb}(x)} {Z_{H}(x)} = \frac{\sum_j \alpha_j C_j(x)}{\prod_{h \in H}(x-h)}.\]
The existence of such a low-degree \(Q(x)\) proves \(C_{comb}(x)\) vanishes over \(H\).
FRI Protocol
The Fast Reed-Solomon Interactive Oracle Proof (FRI) protocol proves the low-degree of \(P(x)\). Ziren optimizes FRI by leveraging:
- Algebraic structure of quartic extension \(\mathbb{F}_{p^4}\).
- KoalaBear prime field \(p = 2^{31} - 2^{24} + 1\).
- Efficient Poseidon2 hash computation.
Three-Phase FRI Procedure
-
Commitment Phase:
-
The prover splits \(P(x)\) into two lower-degree polynomials \(P_0(x)\), \(P_1(x)\), such that: \(P(x) = P_0(x^2) + x \cdot P_1(x^2)\).
-
The verifier sends a random challenge \(\alpha \in \mathbb{F}_{p^4}\)
-
The prover computes a new polynomial: \(P'(x) = P_0(x) + \alpha \cdot P_1(x)\), and sends the commitment of the polynomials to the verifier.
-
-
Recursive Reduction:
- Repeat splitting process for \(P'(x)\).
- Halve degree each iteration until constant term or degree ≤ d.
-
Verification Phase:
- Verifier checks consistency between committed values at random point \(z\) in initial subgroup.
Verifying
Verification contents
To ensure the correctness of the folding process in a FRI-based proof system, the verifier performs checks over multiple rounds using randomly chosen points from the evaluation domain. In each round, the verifier essentially re-executes a step of the folding process and verifies that the values provided by the prover are consistent with the committed Merkle root. The detailed interaction for a single round is as follows:
- The verifier randomly selects a point \(t \in \Omega\).
- The prover returns the evaluation \(p(t)\) along with the corresponding Merkle proof to verify its inclusion in the committed polynomial.
Then, for each folding round \(i = 1\) to \(\log d\) (d: polynomial degree):
-
The verifier updates the query point using the rule \(t \leftarrow t^2\), simulating the recursive domain reduction of FRI.
-
The prover returns the folded evaluation \(P_{\text{fold}}(t)\) and the corresponding Merkle path.
-
The verifier checks whether the folding constraint holds: \(P_{\text{fold}}(t) = P_e(t) + t \cdot P_o(t)\), where \(P_e(t)\) and \(P_o(t)\) are the even and odd parts of the polynomial at the given layer.
-
This phase will end until a predefined threshold or the polynomial is reduced to a constant.
Grinding Factor & Repeating Factor
Given the probabilistic nature of STARK verification, the protocol prevents brute-force attacks by requiring either:
- A Proof of Work (PoW) accompanying each proof, or
- multiple verification rounds.
This approach significantly increases the computational cost of malicious attempts. In Ziren, we employ multiple verification rounds to achieve the desired security level.
Prover Architecture
Ziren zkVM’s prover is built on a scalable, modular, and highly parallelizable architecture that reimagines end-to-end zero-knowledge proof generation for complex programs. The system leverages four tightly-coupled components—Runtime Executor, Machine Prover, STARK Aggregation, and STARK-to-SNARK Adapter—to deliver high-throughput proving, succinct on-chain verification, and exceptional developer flexibility.
1. Runtime Executor
At the heart of the Ziren prover is the Runtime Executor, which orchestrates program execution, manages state transitions, and partitions computation into shards for efficient parallel processing. The workflow consists of:
-
Instruction Stream Partitioning:
The executor splits compiled program binaries (ELF files) into fixed-size execution shards. Each shard represents a self-contained computation slice, enabling pipelined, parallelized execution.
-
Event-Driven Constraint Generation:
As each instruction executes, the runtime dynamically emits algebraic constraints capturing the semantics of register states, memory operations, control flow, and system events.
-
Multiset Hash State Transitions:
Memory consistency and integrity are preserved across shards through cryptographically secure multiset hashing, ensuring tamper-proof execution continuity.
-
Checkpoint & Trace Management:
The executor periodically checkpoints the global execution state, allowing for robust recovery, trace replay, and efficient shard-wise proof generation.
This parallelism and modularity provide a robust foundation for high-performance zero-knowledge proof workflows.
2. Machine Prover
Once shards and execution traces are produced, the Machine Prover takes over, generating STARK proofs for each shard in isolation. This stage features:
-
KoalaBear Field Optimization:
All arithmetic and constraint evaluations are performed in a custom, highly efficient field (KoalaBear), minimizing circuit complexity and maximizing throughput.
-
Poseidon2-based Merkle Matrix Commitment:
The system commits to all polynomial traces using a Merkle Matrix Commitment Scheme (MMCS), leveraging the Poseidon2 hash for both speed and post-quantum security.
-
FRI-based Low-Degree Testing:
Soundness is guaranteed by advanced Fast Reed-Solomon IOPP (FRI) protocols, providing strong assurance of trace integrity with compact commitments.
-
Concurrent Proof Generation:
Proving tasks for all shards are executed in parallel, fully utilizing available CPU cores and significantly reducing end-to-end proving time compared to sequential approaches.
Together, these components deliver high-speed, secure, and scalable zero-knowledge proof generation for arbitrary program logic.
3. STARK Aggregation
Following independent proof generation, STARK Aggregation recursively compresses multiple shard proofs into a single, compact STARK proof. The aggregation process involves:
-
Proof Normalization & Context Bridging:
Shard proofs are converted into a uniform, recursion-friendly format, with mechanisms to preserve and bridge execution context across shard boundaries.
-
Recursive Composition Engine:
The aggregation system recursively combines proofs in multiple layers. The base layer ingests raw shard proofs, performing initial verification and aggregation. Intermediate layers employ “2-to-1” recursive circuits to further compress certificates, and the final composition step yields a single, globally-valid STARK proof.
-
Batch Optimization:
Proofs are batched for optimal parallel processing, minimizing aggregation time and maximizing throughput for large-scale computations.
This multi-phase approach ensures that even highly parallel and fragmented computations can be succinctly and efficiently verified as a single cryptographic object.
4. STARK-to-SNARK Adapter
To enable efficient and universally compatible on-chain verification, Ziren incorporates a STARK-to-SNARK Adapter that transforms the final STARK proof into a Groth16-based SNARK. This pipeline includes:
-
Field Adaptation & Circuit Shrinkage:
Aggregated STARK proofs, originally constructed over the KoalaBear field, are recursively transformed into the BN254-friendly field suitable for Groth16. The proof is compressed and converted in a way that preserves validity while optimizing for size.
-
SNARK Wrapping:
The SNARK wrapping process generates a Groth16-compatible circuit, packages the transformed proof using BN254 elliptic curve primitives, and produces both the final proof and its verification key.
-
On-Chain Optimization:
The resulting Groth16 proof is succinct, supports constant-time verification (O(1)), and can be directly verified by Ethereum and other EVM-based blockchains using standard pairing checks.
This dual-proof pipeline enables Ziren to combine the scalability and transparency of STARKs with the succinctness and universality of SNARKs, making advanced cryptographic verifiability available for all blockchain applications.
STARK Aggregation
Ziren's STARK aggregation system decomposes complex program proofs into parallelizable shard proofs and recursively compresses them into a single STARK proof.
Shard Proof Generation
Ziren processes execution trace proofs for shards through three key phases:
-
Execution Shard
Splits program execution (compiled ELF binaries) into fixed-size batches and maintains execution context continuity across shards.
-
Trace Generation
Converts each shard's execution into constrained polynomial traces and encodes register states, memory operations, and instruction flows.
-
Shard Proof
Generates STARK proofs for each shard independently using FRI with Merkle tree-based polynomial commitments.
The proving pipeline coordinates multiple parallel proving units to process shards simultaneously, significantly reducing total proof generation time compared to linear processing.
Recursive Aggregation
Recursive aggregations are used to recursively compress multiple shard proofs into one. The aggregation system processes verification artifacts through:
-
Proof Normalization
Converts shard proofs into recursive-friendly format.
-
Context Bridging
Maintains execution state continuity between shards.
-
Batch Optimization
Groups proofs for optimal parallel processing.
The aggregation engine implements a multi-phase composition:
-
Base Layer
Processes raw shard proofs through initial verification circuits and generates first-layer aggregation certificates.
-
Intermediate Layers
Recursively combines certificates "2-to-1" using recursive-circuit.
-
Final Compression
Produces single STARK proof through final composition step.
STARK to SNARK
Ziren’s proof pipeline does not stop at scalable STARK aggregation. To enable fast, cost-efficient on-chain verification, Ziren recursively transforms large STARK proofs into succinct SNARKs (Plonk or Groth16), achieving O(1) verification time independent of the original program’s size or complexity.
1. Field Adaptation & Circuit Shrinkage
Purpose
The core challenge in going from STARK to SNARK lies in field compatibility: STARKs natively operate over a large extension field (quartic over KoalaBear Prime), while efficient SNARKs (e.g., Plonk, Groth16) require proofs to be expressed over the BN254 curve field.
Ziren addresses this with a two-phase cryptographic transformation:
a. Proof Compression
- What it does: Recursively compresses the (potentially massive) aggregated STARK proof into a much shorter proof, maintaining all necessary soundness and context.
- How: The compression step leverages FRI-based recursion and context-aware aggregation circuits.
- Key function:
ZKMProver::shrink(reduced_proof, opts)- Internally creates a new aggregation circuit (the “shrink” circuit), which operates over a compressed field representation.
b. Recursive Field Conversion
- What it does: Transforms the compressed proof from the KoalaBear quartic extension field to the SNARK-friendly BN254 field.
- How: Wraps the shrunken STARK proof inside a “wrapping” circuit specifically designed to fit within the constraints and arithmetic of BN254.
- Key function:
ZKMProver::wrap_bn254(shrinked_proof, opts)- Internally creates and executes the wrap circuit, outputting a proof whose public inputs and commitments are fully compatible with SNARKs (Plonk/Groth16).
Engineering Insight
- This two-stage transformation ensures that the final proof is not only succinct, but also verifiable on any EVM-compatible chain or zero-knowledge SNARK circuit.
2. SNARK Wrapping
After adapting the proof to the BN254 field, Ziren applies a final SNARK wrapping step, producing a Groth16 or Plonk proof that is maximally efficient for blockchain verification.
a. Circuit Specialization
- What it does: Specializes the constraint system for the target SNARK protocol, mapping the BN254-adapted proof to a form Groth16/Plonk can consume.
- How: Generates a custom constraint system and witness for the chosen SNARK, reflecting the final state and commitments from the STARK pipeline.
- Key function:
ZKMProver::wrap_plonk_bn254(proof, build_dir)ZKMProver::wrap_groth16_bn254(proof, build_dir)- These invoke circuit synthesis, key generation, and proof construction for the chosen SNARK system.
b. Proof Packaging
- What it does: Encodes and serializes the proof using BN254 elliptic curve primitives, including public input encoding and elliptic curve commitments.
- How: Utilizes efficient encoding routines and cryptographic libraries for serialization and EVM compatibility.
- Key function:
- Still within the above
wrap_*_bn254functions, which return a ready-to-verify SNARK proof object.
- Still within the above
c. On-Chain Optimization
- What it does: Ensures the final proof is optimized for low-cost, constant-time verification on EVM or other smart contract platforms.
- How: Outputs are structured for native use in Solidity and similar VMs, supporting direct on-chain pairing checks (using BN254 curve operations).
- Key output:
- The returned
PlonkBn254ProoforGroth16Bn254Proofcan be immediately used for on-chain verification via Ethereum precompiles or standard verification contracts.
- The returned
Source Mapping Table
| Pipeline Stage | Core Implementation Functions/Structs |
|---|---|
| Proof Compression | shrink |
| Field Conversion/Wrap | wrap_bn254 |
| SNARK Circuit Specialize | wrap_plonk_bn254, wrap_groth16_bn254 |
| Proof Packaging | PlonkBn254Proof, Groth16Bn254Proof |
| On-Chain Verification | Output proof objects for EVM/BN254 verification |
Proof Composition
Ziren zkVM introduces an innovative proof composition system that empowers developers to nest and aggregate cryptographic proofs within zkVM programs. This flexible architecture enables recursive verification, multi-proof aggregation, and modular program upgrades, all while ensuring seamless compatibility with Ziren’s verification framework.
Key Use Cases
-
Privacy-Preserving Computation
Securely process distributed or confidential data by splitting computations into sub-proofs, each protecting its own data fragment, and then aggregating them into a unified, privacy-preserving proof.
-
Cryptographic Proof Nesting
Enable recursive verification of encrypted values—such as zero-knowledge proofs, digital signatures, or homomorphic encryption—without revealing underlying data, thus strengthening both privacy and security.
-
Proof Aggregation & Cross-Chain Verification
Combine independent proofs from multiple sources or blockchains (e.g., Ethereum, other rollups) into a single aggregate proof, facilitating trusted cross-chain data flows and unified validation.
-
Rollup Optimization
Batch and compress large numbers of transaction proofs or state changes into a single, compact proof to improve scalability, reduce verification cost, and maximize on-chain throughput.
-
Modular Program Architecture & Maintainability
Break complex applications into independently verifiable modules, allowing developers to update or upgrade specific components without re-running the entire workflow, increasing maintainability and development agility.
-
Pipeline Proof and Concurrent Verification
Divide lengthy computations into parallel, independently verifiable sub-proofs, streamlining the overall proof generation and validation process for greater efficiency.
Core Components
Ziren packages each proof into an object called a receipt. The proof composition system is built around the idea of recursively verifying receipts inside other zkVM programs. The main components are:
-
Assumption
A formal assertion that declares what needs to be proven, serving as a dependency within the proof composition pipeline.
-
Receipt Claim
A structured statement identifying a specific receipt, which includes metadata such as the program image ID and a SHA-256 commitment to the public input/output, ensuring unique and tamper-evident referencing.
-
Inner Receipt
The fundamental container of a base proof, holding the STARK proof, public values, and the corresponding claim.
-
Assumption Receipt
A conditional receipt that is valid only if its dependencies (assumptions) are fulfilled by other receipts.
-
Composite Receipt
A recursively constructed bundle that aggregates multiple layers of verification, supporting nested proofs and multi-stage validation.
-
Final Receipt
The ultimate artifact that confirms all assumptions have been resolved and all required proofs successfully verified.
Implementation Workflow
Proof Generation
-
Base Proof Generation
Generate a STARK proof for a given (possibly nested) guest program, resulting in an initial inner receipt.
-
Recursive Composition
Use the base and composite receipts as building blocks, recursively aggregate them using Ziren’s aggregation engine, and form higher-level proofs as needed.
-
Final Receipt Assembly
Collect and combine all required receipts (base, assumption, composite) into a final, comprehensive receipt representing the complete proof.
Verification
-
Composite Receipt Verification
Validate the STARK constraints for the main (composite) proof to ensure correctness of the aggregated verification.
-
Inner Receipt Validation
Recursively verify all dependent proofs (assumptions) included within the composition.
-
Receipt Claim Consistency
Check that SHA-256 commitments match across all receipt claims to ensure input/output consistency and cross-proof integrity.
Recursive STARK
Ziren zkVM’s STARK aggregation framework is designed to efficiently prove the correct execution of complex MIPS programs. The system decomposes a single computation trace into parallelizable shard proofs and recursively compresses them into a single succinct STARK proof, ready for SNARK-layer wrapping and blockchain verification.
Shard Proof Generation
The first phase of the Ziren proving pipeline focuses on decomposing program execution and independently proving each segment in parallel. This is achieved through three tightly-coupled stages, each powered by a modular, multi-chip AIR engine (MipsAir).
1. Execution Sharding
Ziren starts by splitting the full program (typically a compiled MIPS ELF binary) into fixed-size execution shards. Each shard represents a window of sequential instructions and maintains precise context bridging—ensuring register state, memory, and all side effects remain coherent at shard boundaries. This enables sharding without losing program integrity.
Implementation Details:
- Key functions:
ZKMProver::get_program(elf)— Loads and prepares the program, setting up all state for sharding.ZKMProver::setup(elf)— Generates proving and verifying keys for all instruction groups.
- AIR Mechanism:
- MipsAir is constructed as an enum, with each variant (“chip”) corresponding to a specific instruction type or system event (e.g., arithmetic, memory, branch, syscall, cryptographic precompiles).
- Each chip maintains its own trace table and constraints; all are initialized at this stage for the full instruction set.
2. Trace Generation (MipsAir Multi-Chip AIR)
Within each execution shard, Ziren simulates the MIPS instruction flow, recording every register transition, memory access, and I/O event. All transitions are encoded into polynomial trace tables—the algebraic backbone of STARK proofs.
Implementation Details:
- Execution & Tracing:
- For every executed instruction, Ziren routes events to the appropriate MipsAir chip. For example, an
ADDtriggersAddSubChip, aLWupdatesMemoryInstructionsChip, aSHA256syscall triggersSha256CompressChip, etc. - Control flow, branching, and exception handling are similarly mapped to dedicated chips.
- Chips such as
CpuChip,ProgramChip, andMemoryGlobalChipcapture global state transitions, while chips likeSyscallChiporKeccakSpongeChiphandle cryptographic or syscall logic.
- For every executed instruction, Ziren routes events to the appropriate MipsAir chip. For example, an
- Trace Table Output:
- Each chip serializes its events into field-valued tables (the “AIR trace”), ensuring all constraints are algebraically represented for later proof.
- This multi-chip design makes it straightforward to extend the VM: new instructions simply require a new chip and AIR variant.
- Key function:
ZKMProver::prove_core(pk, stdin, opts, context)— Runs the program shard, collects execution traces for each chip, and prepares them for proof.- Internally uses:
zkm_core_machine::utils::prove_with_contextfor low-level trace and context handling.
3. Shard Proof Construction
Once the trace for a shard is complete, Ziren independently generates a STARK proof for each shard using a combination of FRI (Fast Reed-Solomon IOP) and Merkle tree-based polynomial commitments. These proofs are self-contained, enabling parallel generation across multiple worker threads or machines.
Implementation Details:
- Proof Orchestration:
- All per-chip traces are aggregated by a
StarkMachine<MipsAir>, which enforces constraints, computes Merkle roots for polynomial commitments, and runs the FRI protocol.
- All per-chip traces are aggregated by a
- Data Structures:
ZKMCoreProof— Aggregates all individualShardProofs.ShardProof— Contains the FRI transcript, Merkle root, and public values for a single execution shard.
- Parallelism:
- Shard proofs are generated in parallel, as all trace and constraint evaluation is isolated to each shard.
Engineering Note:
By leveraging parallelism and a modular multi-chip AIR design, Ziren dramatically reduces total proving time and supports rapid evolution of the underlying VM semantics.
Recursive Aggregation
After all shard proofs are generated, Ziren applies a multi-layer recursive aggregation engine to compress them into a single STARK proof. This process, powered by the RecursionAir engine, enables massive scalability and seamless integration with SNARK-friendly elliptic curves.
1. Proof Normalization & Context Bridging
First, each ShardProof is transformed into a recursive-friendly witness (ZKMRecursionWitnessValues). This step ensures proof structure uniformity and preserves all execution context between adjacent shards—critical for program soundness and security.
Implementation Details:
- Normalization:
- Converts each
ShardProof’s output (public values, Merkle roots, context states) into a fixed, circuit-friendly format. - Prepares all inputs for aggregation in recursive circuits, ensuring that context (memory, registers, I/O, etc.) remains consistent and sound.
- Converts each
- Key function:
ZKMProver::get_recursion_core_inputs(vk, shard_proofs, batch_size, is_complete)
2. Batch Optimization & Input Arrangement
To maximize efficiency, proofs are batched and arranged for recursive composition. The engine organizes these as first-layer inputs—each batch ready to be compressed in the recursion circuit.
Implementation Details:
- Batching Strategy:
- Groups normalized proofs for input to the first aggregation layer, optimizing hardware utilization and recursion circuit size.
- Handles deferred proofs if the total shard count is not a perfect power-of-two.
- Key function:
ZKMProver::get_first_layer_inputs(vk, shard_proofs, deferred_proofs, batch_size)
3. Multi-Phase Recursive Composition (RecursionAir Multi-Chip AIR)
a. Base Layer Aggregation
The engine feeds the normalized, batched shard proofs into initial recursive verification circuits. These circuits verify the correctness of each proof and output first-layer aggregation certificates.
Implementation Details:
- RecursionAir AIR:
RecursionAiris built as an enum, where each variant/chip models a different aspect of recursive aggregation (e.g.,BatchFRIChipfor FRI folding,MemoryVarChip/MemoryConstChipfor state,Poseidon2SkinnyChip/Poseidon2WideChipfor recursive hashing).- Each chip encodes algebraic constraints for verifying subproofs and producing compressed outputs.
b. Intermediate Layers: Recursive Compression
Certificates from the previous layer are grouped (typically “2-to-1”) and recursively combined by deeper aggregation circuits. Each recursion layer reduces the number of certificates by half, until only one remains.
Implementation Details:
- Layered Aggregation:
- Aggregation layers repeat the RecursionAir circuit, each time taking outputs from the previous layer as new inputs.
FriFoldChipandBatchFRIChipare critical for FRI-based recursive combination of subproofs.
c. Final Compression
The final recursion layer outputs a single ZKMReduceProof, representing the proof for the entire program execution.
- Key function:
ZKMProver::compress(vk, core_proof, deferred_proofs, opts)- Recursively calls
recursion_program,compress_program, and—when needed—deferred_programfor full aggregation.
Pipeline Advantages
- Parallel Proof Generation: Sharding the execution trace enables Ziren to exploit all available hardware, scaling from a laptop to a compute cluster.
- Modular, Extensible AIR: Both
MipsAirandRecursionAirare designed as multi-chip enums—adding new instructions, syscalls, or recursive strategies simply requires implementing a new chip and variant. - Efficient Recursive Compression: The multi-layer aggregation pipeline enables succinct proofs even for extremely long or complex program traces.
- Seamless SNARK Integration: The final, aggregated STARK proof is compact and “SNARK-friendly,” ready for fast Plonk/Groth16 wrapping and on-chain verification.
Source Mapping Table
| Pipeline Stage | Core Implementation Functions/Structs | AIR Engines/Structs |
|---|---|---|
| Execution Shard | get_program, setup | MipsAir |
| Trace Generation | prove_core, zkm_core_machine::utils::prove_with_context | MipsAir (multi-chip AIR) |
| Shard Proof | ZKMCoreProof, ShardProof | |
| Normalization | get_recursion_core_inputs, ZKMRecursionWitnessValues | |
| Batch Optimization | get_first_layer_inputs | |
| Recursion/Compress | compress, recursion_program, compress_program, deferred_program | RecursionAir (multi-chip AIR) |
Implementation MipsAir and RecursionAir
MipsAir: Multi-Chip AIR for MIPS Execution
The MipsAir engine acts as the backbone of the zkVM’s MIPS execution trace algebraization. It is constructed as a Rust enum, where each variant (“chip”) models a particular MIPS instruction, memory access, system event, or cryptographic precompile.
Chip Responsibilities
| Chip Variant | Responsibility / Encoded Logic |
|---|---|
ProgramChip | Static program table: instruction fetch, program counter, static code checks |
CpuChip | Main MIPS CPU state: PC, registers, instruction decode/dispatch, cycle tracking |
AddSubChip | Arithmetic: addition/subtraction, overflow detection, flag logic |
MulChip, DivRemChip | Multiplication, division, modulus, including handling for MIPS-specific edge cases |
MemoryInstructionsChip | Memory access: loads/stores, address translation, memory consistency |
MemoryGlobalChip | Global memory state, initialization and finalization of memory regions |
BitwiseChip, ShiftLeft, ShiftRightChip | Bitwise ops, logical/arithmetic shift left/right |
BranchChip, JumpChip | Control flow: conditional branches, jumps, branching logic |
LtChip, CloClzChip | Comparison, leading-zero/count instructions |
SyscallChip, SyscallInstrsChip | System call dispatch, I/O events |
KeccakSpongeChip, Sha256CompressChip, ... | Cryptographic precompiles, including circuit-level hash and EC operations |
| ... | ... (Elliptic curve, BLS12-381/BN254 operations, modular arithmetic, etc.) |
Data Flow
- During simulation, every MIPS instruction and system event is routed to the corresponding chip.
- Each chip:
- Maintains its own trace table, with columns for all relevant fields (inputs, outputs, flags, auxiliary data).
- Defines algebraic constraints that express correct behavior.
- Example:
AddSubChipensures \(z=x+yz = x + y\) and correct overflow flag. - Example:
MemoryInstructionsChipensures memory consistency across reads/writes.
- Example:
- All chips are orchestrated by the
StarkMachine<MipsAir>, which ensures that constraints are enforced both within and across chips (e.g., register handover between CPU and memory chips).
Typical Polynomial Constraint (Example)
-
Addition:
\( \text{AddSubChip: } r_{\text{out}} = r_{\text{in1}} + r_{\text{in2}} \)
-
Memory consistency:
\( \text{MemoryInstrs: } \forall\ (a, v)\ \text{write},\ \mathrm{read}(a)\ \text{must see latest } v \)
-
Branch correctness:
\( \text{BranchChip: } \text{if}\ cond \to PC_{\text{next}} = target \)
-
Cryptographic precompiles (e.g., SHA256 step):
\( \text{Sha256CompressChip: } h_{\text{out}} = \text{SHA256 round}(h_{\text{in}}, w)\ \)
Trace Construction and Proving
- Trace Generation: For every instruction/event, update relevant chip traces and context.
- Proving:
prove_corecalls all chips’ constraint checkers; all traces are committed via Merkle roots; FRI is run for low-degree testing.
Key Call Relationships
MipsAir::chips()— Returns all chips needed for the program.MipsAir::machine(config)— Constructs the STARK machine over all active chips.ZKMProver::prove_core→StarkMachine<MipsAir>::prove— Main proof generation logic; coordinates all chip constraints and witness extraction.
RecursionAir: Multi-Chip AIR for Proof Aggregation
The RecursionAir engine is architected for recursive aggregation and verification of shard proofs. It shares the multi-chip enum structure of MipsAir, but each chip targets aggregation, folding, and recursive hashing.
Chip Responsibilities
| Chip Variant | Responsibility / Encoded Logic |
|---|---|
MemoryVarChip, MemoryConstChip | Carries over and verifies state for variable/constant memory in recursion |
BaseAluChip, ExtAluChip | Encodes base and extension field arithmetic needed for proof normalization or hashing |
Poseidon2SkinnyChip, Poseidon2WideChip | Recursively hashes context or proof artifacts with efficient sponge functions |
BatchFRIChip, FriFoldChip | Aggregates and verifies FRI transcripts/roots for recursive folding of subproofs |
ExpReverseBitsLenChip | Handles bit-reversal, reordering, or compression in the recursive transcript |
SelectChip | Circuit-level selectors/multiplexers for variable context or proof branching |
PublicValuesChip | Maintains and compresses public values through recursion layers |
Data Flow
- Input: All normalized
ShardProofs are transformed into fixed-length witness vectors. - Aggregation:
- Base layer: Inputs are fed into chips modeling recursive FRI, Merkle verification, hash merging.
- Intermediate/final layers: Proofs/certificates are recursively compressed, context is validated at each stage.
- Output: The final layer emits a single, compact, recursively-aggregated STARK proof.
Typical Polynomial Constraint (Example)
-
Recursive FRI folding:
\( \text{BatchFRIChip: } FRI_{\text{agg}} = FRI_{\text{1}} \circ FRI_{\text{2}} \)
-
Recursive hashing:
\( \text{Poseidon2WideChip: } H_\text{out} = \text{Poseidon2}(H_{\text{in}})\ \)
-
Context consistency:
\( \text{MemoryVarChip: } context_{\text{next}} = context_{\text{curr}} + \text{delta} \)
Key Call Relationships
RecursionAir::machine_wide_with_all_chips(config)/machine_skinny_with_all_chips(config)— Build the recursive proof circuit with the chosen hash function variant.ZKMProver::compress→ recursively calls aggregation and compression logic, passing inputs through multiple RecursionAir layers.get_recursion_core_inputs,get_first_layer_inputs— Normalize and batch inputs for the recursive pipeline.
Summary Table: AIR and Chip Mapping
| Phase | Engine/AIR | Key Chips Used | Example Constraint |
|---|---|---|---|
| MIPS Execution Trace | MipsAir | CpuChip, AddSubChip, MemoryInstructionsChip, Sha256CompressChip, ... | \( r_{\text{out}} = r_{\text{in1}} + r_{\text{in2}} \) |
| Shard Proof | StarkMachine | All MipsAir chips | Merkle/Fri roots for all traces |
| Aggregation (Base) | RecursionAir | BatchFRIChip, Poseidon2WideChip, MemoryVarChip | \( H_\text{out} = \text{Poseidon2}(H_{\text{in}})\ \) |
| Aggregation (Layers) | RecursionAir | All aggregation and context chips | Recursive FRI, context bridging |
| Final Proof | RecursionAir | Output chip, public values chip | Output compression, public value mapping |
Continuation
Ziren implements an advanced continuation framework within its zkVM architecture, combining recursive proof composition with multi-shard execution capabilities. This design enables unbounded computational scalability with cryptographically verifiable state transitions while minimizing resource overhead. It has the following advantages:
-
Scalability Shards avoid single proof size explosion for long computations.
-
Parallelism
Independent shard proving enables distributed proof generation.
-
State Continuity
Overall memory consistency checking and consecutive program counter verifying ensures protocol-level execution integrity beyond individual shards.
Session-Shard Structure
A program execution forms a Session, which is dynamically partitioned into atomic shards based on cycle consumption. Each shard operates as an independent local execution with its own proof/receipt, while maintaining global consistency through cryptographic state binding.
Key Constraints
-
Shard Validity
Each shard's proof must be independently verifiable.
-
Initial State Consistency
First shard's start state must match verifier-specific program constraints (i.e., code integrity and entry conditions).
-
Inter-Shard Transition
Subsequent shards must begin at the previous shard's terminal state.
Proof Overflow
-
Shard Execution Environment
Shards operate with isolated execution contexts defined by:
- Initial Memory Image: Compressed memory snapshots with Merkle root verification.
- Register File State: Including starting PC value and memory image.
-
Shard Proof
Prove all instructions' execution in this shard, collecting all reading memory and writing memory records.
-
Session Proof Aggregation
Global session validity requires sequential consistency proof chaining:
- Overall memory consistency checking.
- Program counters consistency checking.
- Combine shard proofs via folding scheme.